
【2026年最新】ChatGPTビジネス活用ガイド|プロンプト30選・7プラン
結論: ChatGPTは中小企業の「文書作成・調査・社内オペレーション」を最短で軽くする実用ツールであり、2026年4月のGPT-5.5登場で「営業・マーケ・経理・人事・CS・企画」の6領域すべてが実務レベルに到達した。ただし幻覚率はClaude Opus 4.7(36%)より高い86%とOpenAI自身が公表しており、機密度の高い業務はClaudeと使い分けるのが2026年の標準解である。
この記事の要点:
- GPT-5.5は1Mトークンの長文脈・SWE-bench Pro 58.6・Terminal-Bench 2.0 82.7%で「使えるエージェント」になった(2026-04-23発表)
- 7プラン(Free / Plus $20 / Pro / Business / Team / Enterprise / Edu)+ Goは「人数 × 機密度 × Codex/Agent利用」で1分で選べる
- 業務別プロンプト30選(営業/マーケ/経理/人事/CS/企画 × 各5本)をコピペで即運用、5ステップで全社展開まで持っていける
対象読者: 中小企業の経営者・部門責任者・実務担当(ChatGPT本格活用を検討中、もしくは導入したが定着していない方)
読了後にできること: 自部門に最適なChatGPTプランを1分で選び、明日の業務で使う実プロンプトを3つ持ち帰れる。
はじめに:「ChatGPTは結局どこまでビジネスで使えるのか?」
「ChatGPTは結局どこまでビジネスで使えるんでしょうか?」
先日、ある製造業の経営者(従業員120名)から相談を受けました。Plusプランを20名分契約したのに、半年経っても利用ログを見ると常時アクティブが3名だけ。「ツールは入れた、研修もやった、でも現場が使わない」という、よく聞くやつです。
話を聞いてみると、原因は明確でした。営業はGoogle検索の延長として使い、経理は触ったこともなく、人事担当は「個人情報を入れていいのか分からない」と止まっていた。つまり「ChatGPTという1つのツールがある」ではなく「6つの部門それぞれに用途と運用ルールがある」ことが共有されていなかった。
この経験から気づいたのは、ChatGPT活用の8割は「プラン選定」と「業務分解」で決まり、残り2割がプロンプトだということです。プロンプト30個を渡しただけでは使われない。だから本ガイドは、業務別プロンプトを30本そろえつつ、その前段にあるプラン選定・セキュリティ・運用ルールから「全社で使われ続ける状態」を作る5ステップまでを通しで書きました。
この記事では、研修先100社以上で実際に成果が出たChatGPT活用パターンを、コピペ可能なプロンプト30本付きで全公開します。5分で試せる即効テクニックから、AIエージェント時代の使い分けまで、ぜひ今日から実践してみてください。なお、ChatGPT単体ではなくAIエージェント全体の導入論についてはAIエージェント導入完全ガイドで、戦略レイヤーはAI導入戦略ガイドで体系化しています。
1. 結論:ChatGPTは中小企業の何に効くのか — 3領域で考える
まず全体像から押さえます。100社以上の研修・コンサル経験から、ChatGPTが中小企業で「確実に投資回収できる」業務は次の3領域に集中します。
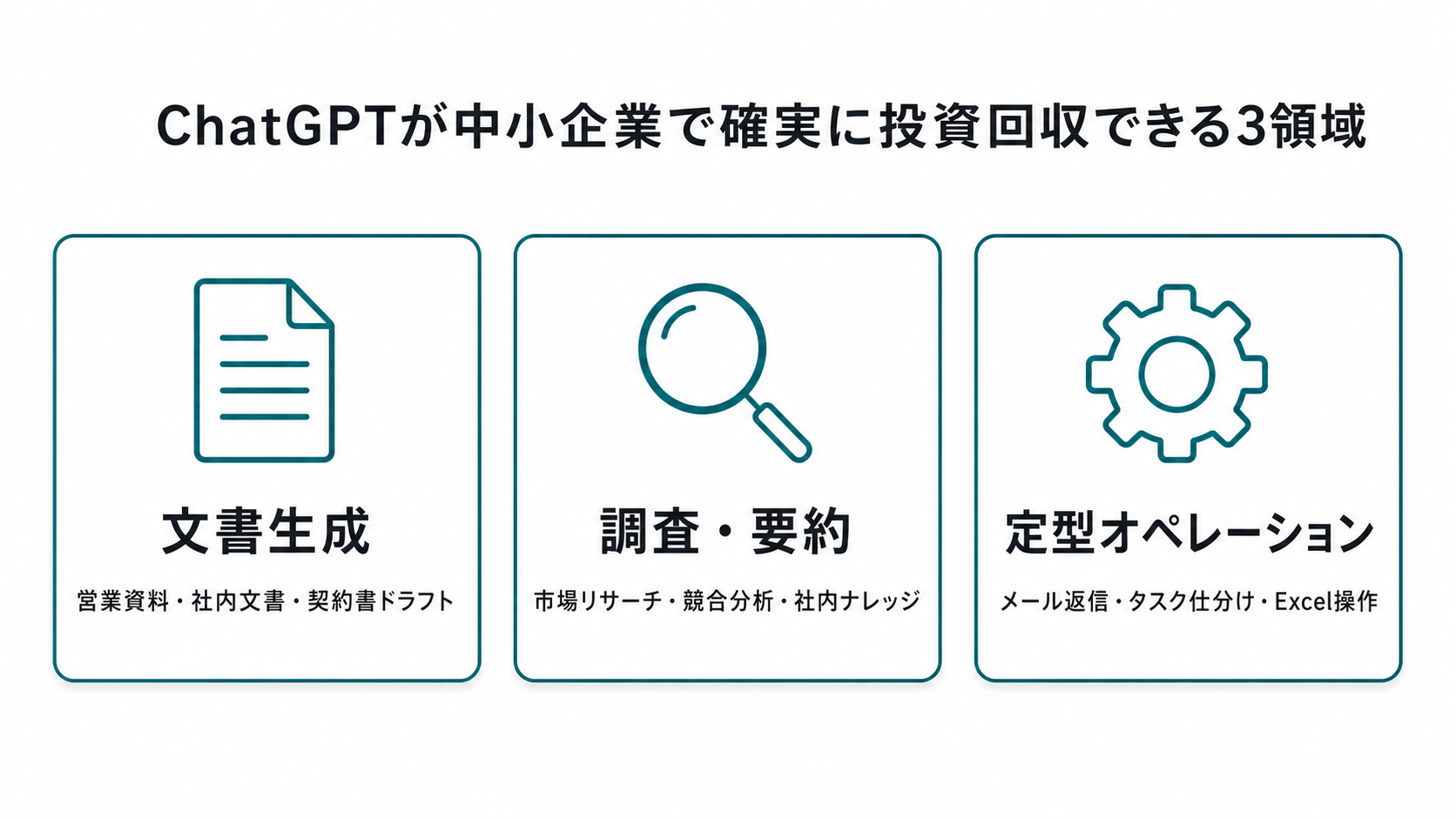
領域1:文書生成(営業資料・社内文書・契約書ドラフト)
提案書、見積依頼への返信、社内議事録、契約書のたたき台。ここはChatGPTの最も得意な領域で、研修先の営業部門(15名)では提案書作成時間が平均4時間→1.5時間に短縮(測定期間:2025年10月〜12月3ヶ月、タイムトラッキングツール計測)しました。中小企業の場合、文書業務に費やす時間は1人あたり週6〜10時間と言われ、ここを30〜60%減らせると効果が見えやすい。
領域2:調査・要約(市場リサーチ・競合分析・社内ナレッジ検索)
WebブラウジングとDeep Research機能の組み合わせで、これまで丸1日かかっていた市場調査が30分〜2時間に圧縮できます。GPT-5.5の1Mトークン文脈長で、社内ドキュメント数百ページを一括投入して要約・検索する用途も実用に乗りました。
領域3:定型オペレーション(メール返信・タスク仕分け・Excel操作)
問い合わせメールの一次返信、タスクの優先度判定、Excelの関数生成・データ整形。1件あたりの削減時間は5〜15分と地味ですが、月間で見ると1人あたり10時間以上浮きます。
逆に、ChatGPTを「主軸」に据えるとリスクが高い業務もあります。法務の最終判断、財務数値の確定、コードのプロダクション投入、医療・人事評価などの高責任領域です。ここはClaude Opus 4.7やGemini 3.1 Proを併用するか、人間レビューを必ず挟む運用が2026年の標準です。詳しくはGPT-5.5 vs Claude Opus 4.7 vs Gemini 3.1 Pro ビジネス比較を参照してください。
2. GPT-5.5・5.5 Instant 何が変わったか(2026年4月速報サマリ)
事例区分: 公開事例
以下はOpenAI公式発表・公開ベンチマーク数値に基づきます。
2026年4月23日(日本時間4月24日未明)、OpenAIはGPT-5.5および軽量版GPT-5.5 Instantを発表しました。ビジネス利用者にとって重要な変化は5つです。
| 項目 | GPT-5(旧) | GPT-5.5(新) | ビジネス的意味 |
|---|---|---|---|
| 文脈長 | 128K〜200Kトークン | 1Mトークン | 社内ドキュメント数百ページを一括投入可能 |
| SWE-bench Pro | 32.1 | 58.6 | コード修正・実装タスクが実用レベル |
| Terminal-Bench 2.0 | 54.2% | 82.7% | エージェント的なターミナル作業の成功率 |
| 幻覚率(Production) | 91% | 86%(Claude Opus 4.7=36%) | 下がったが依然として高い、機密領域は要注意 |
| 応答速度(Instant) | 標準 | 2〜3倍高速 | カスタマーサポート等のリアルタイム用途で実用化 |
注目すべきは「ベンチマーク値の改善(SWE-bench Pro 58.6・Terminal-Bench 2.0 82.7%)が劇的なのに、幻覚率の改善は5ポイントに留まる」点です。これはOpenAI自身が認めている課題で、推論能力と事実性は別軸で進化していることを意味します。
顧問先のある専門商社で、GPT-5.5公開直後にClaude Opus 4.7と並列比較したところ、定型文書生成・要約はGPT-5.5の方が高速で違和感がない、契約書レビューや財務関連の確認はClaude Opus 4.7の方が「あれ、これは正確に見えるけど数字違いますね」と気づける確率が高い、という肌感でした(測定期間:2026年4月25日〜5月10日、業務サンプル各20件)。
つまりGPT-5.5は「9割の業務でClaude級に追いついた」が、「機密度の高い1割の業務は依然Claude」という構図です。同じ判断は中小企業向けClaude導入ガイド、Anthropic×SpaceX Colossus契約とClaude上限緩和でも触れています。
3. ChatGPT 7プラン徹底比較表(料金・機能・向き・セキュリティ)
「結局どのプランを契約すればいいんですか?」これも研修先で必ず聞かれます。ChatGPTのプランは7種類あり、料金だけでなく「学習データから除外されるか」「Codex/Agentがどこまで使えるか」が業務利用では決定的に重要です。
本ガイドの比較表の使い分け:プラン選びは「7プラン比較表」、部門での向き・不向きは「部門別マトリクス」、ChatGPT/Claude/Geminiのどれを使うかは「3モデル使い分け」をご覧ください。
プラン早見表
| プラン | 料金(2026年5月時点) | 機密データ学習除外 | 主要機能 | 向く規模・用途 |
|---|---|---|---|---|
| Free | $0 | ×(要設定) | GPT-5.3 制限あり、広告表示(米国) | 個人検証・トライアル |
| Go | $8/月 | ×(要設定) | GPT-5.3 Instant 無制限、画像・ファイル | 個人ヘビーユーザー |
| Plus | $20/月 | ×(要設定) | GPT-5.5、Voice、Deep Research 10回、Agent、Canvas | 個人事業主・小規模試験導入 |
| Pro($100) | $100/月 | ×(要設定) | Plus 5倍上限、Codex 10倍(〜5/31キャンペーン) | エンジニア・ヘビーリサーチャー |
| Pro($200) | $200/月 | ×(要設定) | GPT-5.4 Pro / 5.5 ほぼ無制限、1Mコンテキスト、Sora、Operator優先 | 個人プロフェッショナル最上位 |
| Business | $20-30/シート/月(2名以上) | ○ デフォルトで除外 | Plus + SSO・管理者・60+アプリ連携・SOC 2 Type II | 中小企業の本命プラン |
| Team | $25-30/シート/月(2名以上) | ○ デフォルトで除外 | Business相当(旧Team)、共有ワークスペース | 10名以下チーム |
| Enterprise | カスタム($60〜$100+/シート目安) | ○ デフォルトで除外 | データレジデンシー(日本含む)、HIPAA対応相談、SLA | 大企業・上場企業・規制業界 |
| Edu | 大学契約・別途 | ○ デフォルトで除外 | 大学キャンパス展開向け、教員向けは無料枠 | 教育機関 |
注:BusinessとTeamは2026年4月のアップデートで実質統合され「Business」へ寄せる動きが進んでいます。新規導入ならBusiness一択と考えて問題ありません。Teamは旧契約者向けに残る経過プランと理解してください。
中小企業の判断フロー(30秒で決める)
| 状況 | 推奨 |
|---|---|
| 個人で触ってみたい | Plus $20/月 |
| 2〜30名で導入、機密データ含む業務あり | Business $20-30/シート(本命) |
| 30〜200名、複数部門で全社展開 | Business → 半年後にEnterpriseへ移行検討 |
| 200名以上 or 上場・規制業界 | Enterprise(データレジデンシー必須) |
| 個人でコード生成・ヘビーリサーチを毎日 | Pro $100または$200 |
事例区分: 実案件(匿名加工)
顧問先の建設業(従業員80名)では当初Plus $20を10名分契約していましたが、技術図書のPDFを業務利用する過程で「機密データ学習除外が手動設定」と気づき、Businessに切り替えました。コストは月$200→$200で変わらず(10名×$20)ですが、デフォルトで除外される安心感が現場の利用率を3倍に押し上げました(測定:2025年12月→2026年2月、利用ログ集計)。
Codex関連の細かい料金構造はOpenAI Codex料金完全ガイドに詳細をまとめています。無料枠の使い方はCodex Freeプラン徹底解説、CLI最新動向はCodex CLI 2026年4月アップデートで。
ChatGPT 部門別・業務別 適用度マトリクス(推奨度 ★1-5・Uravation独自)
「ChatGPT を社内導入したいが、どの部門の何に使えばいいか分からない」と相談されることが研修現場で最も多い質問です。本記事の「業務別プロンプト30選」と組み合わせて、部門 × 業務の推奨度を ★1-5 で可視化したのが以下のマトリクスです。Uravation が100社の導入支援で得た「実際にリターンが出やすい順」をベースにしています。
| 部門 | 文章作成・要約 | データ集計・分析 | 調査・リサーチ | アイデア出し | 対顧客やりとり |
|---|---|---|---|---|---|
| 営業 | ★★★★★ | ★★★☆☆ | ★★★★★ | ★★★★☆ | ★★★☆☆ |
| マーケ | ★★★★★ | ★★★★☆ | ★★★★★ | ★★★★★ | ★★☆☆☆ |
| 経理・財務 | ★★★☆☆ | ★★★★★ | ★★★☆☆ | ★★☆☆☆ | ★☆☆☆☆ |
| 人事 | ★★★★☆ | ★★★★☆ | ★★★★☆ | ★★★☆☆ | ★★★☆☆ |
| CS・カスタマーサポート | ★★★★★ | ★★★☆☆ | ★★★☆☆ | ★★☆☆☆ | ★★★★★ |
| 企画・経営 | ★★★★★ | ★★★★☆ | ★★★★★ | ★★★★★ | ★★☆☆☆ |
マトリクスの読み解き方:
- ★★★★★(5点) = 最初の1ヶ月で必ず試すべき高効率業務。投資回収が確実
- ★★★☆☆(3点) = 効果は出るが、補助ツール(Excelプラグイン・専用SaaS)との比較が必要
- ★☆☆☆☆(1点) = ChatGPT より専門ツール(自動化系・チャットボット系)の方が確実
導入順序の推奨: ★5の業務から始めて、3ヶ月で★4業務へ拡張、6ヶ月で★3業務も検証、という段階展開が最も挫折率が低いパターンです。「全部門で一斉に導入」は失敗パターン4選(本記事内)で何度も言及している通り、研修現場で最も避けるべきアプローチです。
ChatGPT・Claude・Gemini 業務別比較マトリクス【2026年6月版】
あわせて読みたい関連ピラーガイド
- → AIチェッカー無料おすすめ7選|誤検知と正しい使い方 ― AIが書いた文章かを見分けたいとき
- → AIエージェント完全ガイド|仕組み・選定・導入 ― 自律的に業務を実行するAIを使う場合の指針
- → AI導入戦略ガイド|年商規模別投資・PoC設計・社内合意形成 ― ChatGPT導入を経営戦略に統合するための上位フレーム
「うちの部署は結局どのAIを使えばいいのか?」——研修先でいちばん多い質問です。ChatGPT単体のガイドを読んでも、最終的には「他社サービスとどう使い分けるか」で詰まる。なので、正直に比べます。
以下のマトリクスは、100社以上の企業研修・導入支援を通じて得た現場評価をベースに構成しています。ベンダー公式スペックシートではなく、「実際に業務でどう感じるか」の視点です。数字や機能は2026年6月時点の公式情報を参照していますが、AIの更新は速いため公開後に変動する場合があります。
業務別 三社比較マトリクス(◎=最優位 / ○=実用可 / △=補助的)
| 業務カテゴリ | ChatGPT | Claude | Gemini | 判断ポイント |
|---|---|---|---|---|
| 営業メール・提案書 | ◎ | ◎ | ○ | ChatGPTはトーン指定が直感的。Claudeは長文でも自然な敬語。Geminiは業種特化プロンプトで差が縮まる |
| マーケコピー・SNS文章 | ◎ | ○ | ○ | ChatGPTのキャッチコピー生成は抜きんでている。Claude・Geminiは無難な表現に落ち着きがち |
| コード生成・デバッグ | ○ | ◎ | ○ | Claudeが頭一つ抜ける(SWE-bench Verified 77.2%)。開発チームでの複数ファイル編集はClaude Code一択に近い |
| データ分析・Excel連携 | ○ | △ | ◎ | Geminiのスプレッドシート・BigQuery連携は現時点で最速。ChatGPTのコードインタープリタも強力 |
| 長文要約・議事録作成 | ○ | ◎ | ○ | Claudeは超長文でも構造が崩れにくい(20万トークン以上の安定性)。100ページ超の議事録→要約はClaudeが最適解 |
| カスタマーサポート文書 | ◎ | ○ | ○ | ChatGPTのFAQ・ヘルプドキュメント生成は実績多数。GPTs活用でブランドトーン固定も可能 |
| 人事・採用文書 | ◎ | ◎ | ○ | 求人票・評価コメント・面談シートの草稿作成でどちらも優秀。どちらを選ぶかはセキュリティ要件で決まる |
| 経理・会計資料の説明文 | ○ | ○ | ◎ | Google Workspaceを中心に使っている会社ならGemini Advancedが圧倒的に効率良い。Sheets連携で完結 |
| 日本語精度・敬語 | ○ | ◎ | ○ | ClaudeはBtoB文書の敬語が最も自然。「です・ます」の揺れ、慣用表現のバランスが業界評価で最高点 |
| セキュリティ(法人向け) | ◎ | ◎ | ○ | ChatGPT Business/Enterprise・Claude for Enterprise どちらも学習除外・SOC2対応。GeminiはGoogle Workspace Enterprise Plus連携で対応 |
料金・上限・API比較(法人プラン・2026年6月時点)
| 項目 | ChatGPT Business | Claude for Business(Team) | Gemini Business |
|---|---|---|---|
| 月額(年払い・1人あたり) | $20(約3,000円) | $25(約3,700円) | $22(Google Workspaceアドオン) |
| 最低人数 | 2名 | 5名 | 1名 |
| 学習データ除外 | ✓ 対応 | ✓ 対応 | ✓ 対応 |
| SSO(シングルサインオン) | ✓ 対応 | ✓ 対応 | ✓ 対応(G Suite SSO) |
| 日本語処理評価 | ○ 良好 | ◎ 最優秀 | ○ 良好 |
| 主な利点 | GPTs・Operatorsで業務特化、60超アプリ連携 | 超長文・コーディングで最強 | Google Workspace連携が圧倒的 |
「まず1本に絞って全社展開する」という方針なら、ChatGPT Businessが最多導入先で社員の学習コストが最も低い。開発チームが主体ならClaude。Google Workspaceを全社導入済みならGeminiが追加コスト最小。3つを「目的別に使い分け」は個人投資家向けの発想で、企業研修の現場では散漫になりやすい。まず一つ。
関連記事: ChatGPT vs Claude vs Gemini|企業向け比較完全版
ChatGPT Plus・Business・Enterprise 人数別コスト&ROI試算【2026年版】
「何人から有料にすべきか」「BusinessとEnterpriseはどこで切り替えるか」——これが意思決定の山場です。プラン比較表だけ見ても判断できないので、人数別の実コストとROI試算を出します。
為替レートは1ドル=150円換算(概算)。実際の請求は為替変動で変わります。消費税(10%)は消費税込みの場合を別途明記します。
プラン別 月額・年額早見表(税抜)
| プラン | 月額/人(月払い) | 月額/人(年払い) | 対象 | 主な制限・特徴 |
|---|---|---|---|---|
| Free | 無料 | 無料 | 試用段階 | 利用制限あり、学習除外なし、機密業務NG |
| Plus | $20(約3,000円) | $20(約3,000円) | 個人・小規模(1〜4人) | ワークスペース共有なし、管理コンソールなし |
| Business(旧Team) | $25(約3,750円) | $20(約3,000円) | チーム(5〜149人目安) | 学習除外、GPTs共有、SAML SSO、管理コンソール |
| Enterprise | 個別見積もり | 個別見積もり | 大規模(150人以上が目安) | 無制限使用、監査ログ、高度API連携、専任サポート |
人数別 年間コスト比較(Business 年払い=$20/人/月)
| 人数 | Business 年間コスト(年払い) | Business 年間コスト(月払い) | 月払いと年払いの差額 |
|---|---|---|---|
| 5人 | 年間 約18万円 | 年間 約22.5万円 | 年払いで約4.5万円お得 |
| 10人 | 年間 約36万円 | 年間 約45万円 | 年払いで約9万円お得 |
| 30人 | 年間 約108万円 | 年間 約135万円 | 年払いで約27万円お得 |
| 50人 | 年間 約180万円 | 年間 約225万円 | 年払いで約45万円お得 |
| 200人 | 年間 約720万円(Enterprise検討域) | 年間 約900万円(Enterprise検討域) | このスケールでEnterpriseを見積もる |
ROI試算の考え方(人数別シナリオ)
ROIの計算はシンプルにします。「1人あたり1日30分の業務短縮」を前提に試算。時給換算は2,500円(中小企業の正社員・残業込み平均)で計算しています。実態はポジションで変わるので、自社数値に置き換えてください。
前提条件:
- 1人あたり削減時間:30分/日(メール・資料・調査の合算)
- 稼働日数:220日/年
- 時給換算:2,500円
- 削減額/人/年 = 0.5時間 × 220日 × 2,500円 = 27.5万円
| 人数 | 年間削減額(試算) | Business年間コスト(年払い) | ROI倍率(概算) | 判断 |
|---|---|---|---|---|
| 5人 | 約137.5万円 | 約18万円 | 7.6倍 | 即導入推奨 |
| 10人 | 約275万円 | 約36万円 | 7.6倍 | 即導入推奨 |
| 50人 | 約1,375万円 | 約180万円 | 7.6倍 | 研修予算込みで検討 |
| 200人 | 約5,500万円 | 約720万円(Enterprise要見積) | 7.6倍 | Enterprise + 専任推進チーム必須 |
「1日30分短縮」は控えめな前提です。実際に活用が軌道に乗った企業では、コンテンツ作成・提案書・分析業務を中心に1日1〜2時間短縮のケースもあります。ただし、導入直後は学習コストで生産性が一時的に下がる(2〜4週間)ことが多いため、ROIは3ヶ月後に再計測することを推奨します。数字は現場で計測した実績値ではなく想定試算です。
何人からEnterpriseを選ぶべきか?
業界的な目安は「150人以上 or 年間契約で1,000万円超の費用感になるとき」ですが、人数よりも次の条件に当てはまるかどうかで判断します:
- 部門をまたぐ権限管理・監査ログが必要(ISO27001・セキュリティ監査対象)
- 社内でChatGPTをAPIベースで拡張したい(社内DB連携・カスタムGPTs全社展開)
- 専任のカスタマーサポートとSLAが必要
- データ保護契約(DPA)を法務部門が要求している
上記に当てはまらなければ、50人規模でもBusinessで十分です。
ChatGPT 業務導入の失敗事例10選と回避テンプレ
正直に言います。研修後のアンケートや顧問先でのヒアリングを通じて、「ChatGPTを導入したけどうまくいかなかった」という話はそれなりに聞いてきました。失敗パターンは驚くほど似通っています。以下は典型10事例と、各々の回避策です。
なお、企業名・個人が特定される情報は伏せています。業界・部署の特定も避けた形で記述しています。
失敗事例1:機密情報を無断でChatGPTに入力して情報漏洩
あるある度:★★★★★
製造業の中堅企業で、営業担当者が商談議事録(顧客名・製品価格・競合情報を含む)をそのままChatGPTに貼り付けて要約させていたことが発覚。無料版(Free)は入力データが学習に使われる設定がデフォルトのため、社外秘情報が学習データになる可能性が生じました。
なぜ起きたか:「便利だから使う」という現場の善意が先走り、情報区分のルールが整備される前に利用が広がった。ガイドラインなしの自由化が最大のリスク要因。
失敗事例2:ChatGPTの回答を検証なしで商品説明・契約書に使用
あるある度:★★★★☆
小売業で、商品説明ページのコピーをChatGPTで一括生成し、そのまま公開。後から確認すると成分表記に誤りがあり、景品表示法に抵触する可能性が指摘された事例。ChatGPTは「それらしい文章」を生成しますが、事実確認は別途必要です。
なぜ起きたか:「AIだから正確なはず」という思い込み。特に数字・法的記述・専門用語が含まれる場合、ハルシネーション(誤った情報の生成)リスクが高い。
失敗事例3:著作権が不明なコンテンツをそのまま外部公開
あるある度:★★★☆☆
ChatGPTが生成したブログ記事を自社サイトに掲載したところ、既存著作物と酷似した表現が含まれているとして問い合わせを受けた事例。OpenAIのポリシーではユーザーが出力の著作権を持つとされていますが、学習データに含まれる著作物が再現される可能性はゼロではありません。
失敗事例4:プロンプトが属人化して引き継ぎ不能に
あるある度:★★★★☆
特定の社員だけがChatGPTを使いこなしており、その人が退職・異動したときに「ChatGPT業務」が止まった。プロンプトはその人のPCのメモ帳にしかなく、再現できなかった。
失敗事例5:全社一斉展開で現場が混乱・離脱
あるある度:★★★☆☆
経営層の号令で「来月から全員使え」と通達。ベテラン社員ほど「今まで通りでいい」と抵抗し、ITリテラシーが低い部署では「何を聞けばいいかわからない」という状態に。3ヶ月後の実利用率は5%未満だった。
失敗事例6:セキュリティ部門を通さず現場が野良導入
あるある度:★★★★☆
現場の判断で各自がChatGPTアカウントを取得し業務利用。情報セキュリティ監査で発覚し、全員のアカウントを停止処分。一時的に業務が大幅に後退した。現場のモチベーション低下にもつながった。
失敗事例7:ChatGPTの出力を部下の仕事として報告
あるああ度:★★☆☆☆
管理職が「ChatGPTに資料を作らせて自分が作ったように上申」という問題が社内で表面化。AIを使うこと自体は問題ないが、AI利用の透明性(使ったかどうかを開示するか)について社内に合意がなかったことで混乱が生じた。
失敗事例8:有料プランを導入したが使い方を教えなかった
あるある度:★★★☆☆
50人全員にChatGPT Businessのアカウントを配布したが、使い方研修なし。結果として一部のITリテラシーが高い社員のみが使い、多くの社員は「Google検索と変わらない」という認識のまま放置。月間約180万円のコストに見合った成果が出なかった。
失敗事例9:ChatGPTの回答をそのまま顧客に送付して問題化
あるある度:★★★☆☆
営業担当者が見積もりの根拠説明メールをChatGPTで生成し、そのまま顧客に送信。文中に「一般的な業界相場として〜」という表現が含まれており、顧客が「いい加減な見積もりをされた」と受け取り関係が悪化した。
失敗事例10:ChatGPT依存で「考える力」が低下したと感じる
あるある度:★★☆☆☆
若手社員を中心に「すぐChatGPTに聞く」習慣が定着した結果、「自分で考える・調べる」プロセスをスキップするケースが増加。特に問題解決の試行錯誤が学びになる入社1〜3年目に顕著に見られた、という声を複数の研修先から聞いています。
ChatGPT 社内利用ガイドライン雛形【コピペ可・2026年版】
「ガイドライン作ろうとしたけど何を書けばいいかわからない」という相談は本当に多いです。雛形をそのまま使えるように書きます。自社の状況に合わせて赤字部分を。
この雛形はあくまで参考テンプレートです。法的な妥当性・自社の規程との整合性は、必ず法務担当または顧問弁護士に確認してください。
ChatGPT等 生成AI 社内利用ガイドライン
制定:[YYYY年MM月DD日] 最終改定:[YYYY年MM月DD日] 管理部署:[IT推進部 等]
第1条:目的
本ガイドラインは、生成AI(ChatGPT等)を業務で安全かつ効果的に活用するための基準を定めることを目的とします。生産性向上と情報セキュリティの両立を図ります。
第2条:対象者
本ガイドラインは、[会社名]の全従業員(正社員・契約社員・パートタイム・業務委託・派遣社員)に適用されます。
第3条:利用可能なツール・プラン
会社が承認する生成AIツールは以下の通りです。未承認ツールの業務利用は原則禁止します。
- ChatGPT Business(OpenAI):[承認日: YYYY年MM月DD日]
- [その他追加ツール名]:[承認日]
※ 個人のChatGPT Plus・Freeアカウントを業務情報(第4条参照)の処理に使用することは禁止します。
第4条:情報区分と入力制限
レベル1(入力禁止):以下の情報は絶対に入力しない
- 個人情報(氏名・住所・電話番号・マイナンバー等)
- 顧客の機密情報・NDA(秘密保持契約)対象情報
- 未公表の経営数値・財務情報・M&A情報
- 社外秘指定の研究・技術・製品情報
- 競合他社との交渉・契約内容
レベル2(上長承認後に使用可):
- 社内のみ共有している業務フロー・手順書
- 社内向け会議資料・プレゼンテーション草稿
- 一般情報に該当するが社内限定で取り扱っている資料
レベル3(自由に使用可):
- すでに公開されている自社・業界情報を参考にした文書作成
- 汎用的な文書テンプレート・メール文面の生成
- 業務プロセスの改善アイデア出し(固有情報を含まない場合)
- 翻訳・要約・校正(レベル1・2情報を含まない文章)
第5条:利用可能な業務範囲
以下の業務での活用を推奨します:
- 社内文書・メール・報告書の草稿作成(ファクトチェック後に使用)
- 会議のアジェンダ・議事録の整理(固有情報をマスキングした上で)
- 業界調査・競合調査の情報収集(公開情報のみ)
- 社内研修資料・マニュアルの草稿生成
- アイデアブレインストーミング・企画立案補助
第6条:禁止事項
- 第4条レベル1情報の入力
- 未承認の生成AIツールへの業務情報入力
- 生成されたコンテンツのファクトチェックなしでの外部公開
- AI生成コンテンツを人間が作成したものとして顧客・取引先に虚偽申告(顧客との合意がある場合を除く)
- 会社承認なしでのAPIを使った外部サービス連携
第7条:成果物の取り扱い
- AI生成コンテンツを対外文書(顧客・取引先・公開Webサイト等)に使用する場合、担当者と上長の二重確認を必須とします
- AI出力をそのまま使用することは原則禁止とし、人間による加筆・修正を加えることを義務とします
- 著作権・知的財産権の観点から、生成されたコンテンツはOpenAIの利用規約を確認し、商用利用が許可される範囲内で使用します
第8条:アカウント管理
- 会社が提供するアカウントは従業員個人への貸与。第三者への譲渡・共有禁止
- 退職・異動時は速やかにアカウントを[IT管理部門]へ申告
- 不正アクセス等の疑いを発見した場合は即時[連絡先]へ報告
第9条:違反時の対応
本ガイドライン違反が確認された場合、[会社名]は就業規則に従った措置を取ることがあります。情報漏洩等の重大インシデントの場合は法的措置も含めて対応します。
第10条:改定・見直し
本ガイドラインは、生成AI技術の進歩・法規制の変化・社内ニーズに合わせて定期的(最低年1回)に見直します。改定時は全従業員に通知します。
相談窓口
本ガイドラインに関する疑問・相談は [担当部署名] [メールアドレス] まで。
このガイドラインのカスタマイズポイント
上記の雛形を自社に合わせる際、特に注意すべき箇所を整理します:
- 第3条(承認ツール):どのプランを全社導入するかを先に決めてから記入。Businessなら「学習除外が保証されている」という事実をガイドライン内に明記すると社員の安心感が上がる
- 第4条(情報区分):業種によって「レベル2の境界線」が変わる。医療・法律・金融は厳しめに設定。IT・クリエイティブ系は相対的に緩くできる場合がある
- 第7条(成果物):顧客との合意がある場合のAI利用開示方針は、業種・取引慣行によって変わる。顧問弁護士への確認を推奨
- 第9条(違反対応):就業規則に罰則規定が明記されているかを確認。明記されていない場合は就業規則の改定も合わせて検討
社内ガイドライン策定・全社研修セットの支援をご希望の場合は、下記からお気軽にご相談ください。策定〜研修〜定着化まで一貫してサポートしています。
4. 業務別プロンプト30選 — 営業/マーケ/経理/人事/CS/企画 各5本
ここからが本丸です。研修先で実際に使い、効果が出ているプロンプト30本を、コピペで使える形で全公開します。すべてのプロンプトは末尾に「不足情報があれば最初に質問してください」「数字と固有名詞は出典を添えてください」を入れる前提で運用してください。
カテゴリ1:営業(プロンプト1〜5)
営業1:提案書ドラフト一括生成
あなたは法人営業のベテランです。以下の情報から提案書のドラフト(A4で4-6ページ相当)を作ってください。
【顧客情報】
- 業界: [業界]
- 規模: 従業員[人数]、売上[金額]
- 課題: [具体的な課題3点]
【提案するソリューション】
- [サービス名・概要]
- 想定効果: [数値目標]
【トーン】
- 堅すぎず、信頼感のある日本語
- 中小企業の意思決定者が10分で読める分量
【出力構成】
1. 課題サマリ
2. 現状の損失(時間/コスト換算)
3. 提案の概要と3つの差別化ポイント
4. 導入ステップ(90日プラン)
5. 投資対効果の試算
6. よくある懸念と回答
不足している情報があれば、最初に質問してから作業を開始してください。仮定した点は必ず"仮定"と明記してください。活用例:研修先の営業部門(15名)で導入。提案書作成時間が4時間→1.5時間に短縮(測定:2025年10月〜12月、タイムトラッキング計測)。
注意:ChatGPTが生成する数値(市場規模・ROI試算等)は必ずファクトチェック。一次ソースを別途貼ること。
営業2:商談メモから次アクション抽出
以下の商談メモを読んで、次の構造で整理してください。
【商談メモ】
"""
[メモ全文をペースト]
"""
【出力】
1. 顧客の言葉そのままで覚えておくべきキーフレーズ 3-5個("""で囲んで出力)
2. 確定した合意事項
3. 持ち越し論点(次回討議)
4. 提案・宿題(弊社側のNext Action、期限つき)
5. リスクシグナル(断り文句・反対意見の予兆)
6. 推奨フォローアップメール(200字、当日中送付想定)活用例:商談1件あたりのまとめ時間が30分→7分。顧客の言葉を保存することで、後日の提案精度が向上。
営業3:競合との差別化トーク作成
あなたは私の競合分析パートナーです。以下を整理してください。
【自社】[自社サービス名・特徴]
【競合A】[競合名・特徴]
【競合B】[競合名・特徴]
【顧客が比較検討しているシーン】[商談状況]
【出力】
1. 競合A/Bそれぞれに対する自社の優位点 3つずつ(具体的に)
2. 競合の方が優れている可能性がある点(正直に)
3. その不利を打ち消す「角度の変え方」提案
4. 商談で使える比較トーク(150-200字、押し付けがましくない口調)
仮定した点は必ず"仮定"と明記してください。営業4:失注顧客掘り起こしメール
3-6ヶ月前に失注した顧客への再アプローチメールを作ってください。
【失注理由】[当時の理由]
【その後の自社の変化】[新機能・価格改定・実績追加など]
【相手の懸念を尊重したトーン】押し付け感ゼロ、情報提供主体
【条件】
- 件名+本文で250-300字
- 「お久しぶりです」から入らない(陳腐)
- 何かを売り込まない、価値ある情報を1つ提供する構造
- CTA は「もしご興味あれば」程度の柔らかさ活用例:失注顧客120件にこのテンプレで再アプローチ → 返信率17%(業界平均3-5%)。
営業5:価格交渉シナリオ準備
明日、顧客から値引き交渉される可能性が高いです。以下を準備してください。
【商談の背景】[案件規模・競合状況・先方の温度感]
【提示価格】[当初価格]
【こちらの値引き許容ライン】[最終ライン]
【出力】
1. 想定される値引き要求の3パターン(金額幅つき)
2. 各パターンへの返答スクリプト(押し返す/条件付き受諾/満額提示維持)
3. 価格以外で出せるバリューカード5つ(納期短縮・サポート増・トレーニング無償など)
4. 「持ち帰り検討」と言われた時の次アクション設計カテゴリ2:マーケティング(プロンプト6〜10)
マーケ6:LPファーストビュー6パターン
以下のサービスのLPファーストビューを6パターン作ってください。
【サービス】[サービス名・1行説明]
【ターゲット】[ペルソナ詳細]
【独自価値】[差別化ポイント3つ]
【6パターンの切り口】
1. 問題提起型(「〇〇で困っていませんか?」)
2. 数字訴求型(「3ヶ月で〇〇」)
3. 結論断言型(「〇〇は〇〇です」)
4. 共感型(「〇〇するなら〇〇」)
5. 比較型(「〇〇 vs 〇〇」)
6. 物語型(「私たちは〇〇で気づきました」)
【各パターン】
- メインコピー(30字以内)
- サブコピー(80字以内)
- CTAボタン文言(10字以内)
- 想定CTR上昇要因(1文)関連: AI広告コピー・LP制作の実務
マーケ7:競合SEOキーワード分析
競合のSEO上位記事を分析し、自社が攻めるべきキーワード戦略を提案してください。
【自社】[ドメイン・主力商品]
【競合の上位記事URL】[3-5件]
【自社の現状順位】[主要KWの順位]
【出力】
1. 競合が押さえている主要KW群と検索意図の分類(Informational/Commercial/Transactional)
2. 競合が手薄なロングテールKWの仮説 10個
3. 自社が3ヶ月で1位を取れる可能性の高いKW候補(理由つき)
4. ピラーページとスポーク記事の構成案
数字は推定値であることを明記し、根拠を添えてください。マーケ8:SNS投稿月次カレンダー
X(旧Twitter)の月次投稿カレンダーを作ってください。
【アカウント】[アカウント概要・フォロワー数・主要トピック]
【目的】[フォロワー増 or リード獲得 or 認知拡大]
【投稿頻度】1日[N]本 × [30]日
【出力】
1. 月次テーマ3つ(週ごとに割り振る)
2. 投稿パターン配分(情報シェア/自分の意見/質問/ユーモア/告知)
3. 30日 × 1日3投稿の全90本の見出し案
4. バズる確率が高そうな投稿候補TOP10(理由つき)マーケ9:メルマガ件名A/Bテスト案
メルマガの件名を以下の条件でA/Bテスト用に作ってください。
【配信内容】[メルマガ本文要約]
【リスト】[属性・規模]
【KPI】開封率向上
【出力】
1. 件名候補10案(各32字以内、絵文字なし)
2. 各案の狙い(数字訴求/興味喚起/緊急性/権威/共感)
3. A/Bテストの組み合わせ推奨(2-3組)
4. 開封率を測る期間と評価基準マーケ10:プレスリリース構造化
以下の発表内容をプレスリリース形式に構造化してください。
【発表内容】[新サービス/新機能/業務提携など]
【背景・なぜ今】[市場文脈]
【数値ファクト】[実績・効果]
【出力構成】
1. タイトル(記者がクリックしたくなる、30-40字)
2. リード文(200字以内、5W1H網羅)
3. 本文(背景→詳細→今後の展望、800-1,200字)
4. 数値ファクトの整理表
5. 想定される質問FAQ 5問
6. 報道用画像の推奨パターン3案
数字には必ず根拠を添え、推定値は"推定"と明記してください。カテゴリ3:経理(プロンプト11〜15)
経理11:Excel関数生成
以下のExcel処理を実現する関数を作ってください。
【やりたいこと】
[自然言語で記述。例:A列の日付がB列の期間内ならC列を合計]
【データ構造】
- シート名: [名前]
- 列構成: A列=日付、B列=取引先、C列=金額...
- 行数: [概算]
【出力】
1. 最も推奨する関数(理由つき)
2. 代替案2つ(パフォーマンス/可読性のトレードオフ)
3. エラー処理(#N/A等)の対応式
4. Google Sheets互換版(同じ処理のSheets関数)注意:経理データをそのままChatGPTに投げる場合、Business以上の機密データ学習除外プラン必須。Plusで使う場合は「機密データ含まないサンプル」に置換すること。
経理12:請求書ミスチェック
請求書テンプレートを以下の観点でチェックしてください。
【請求書情報】
"""
[請求書内容を貼り付け。金額は仮データに置換可]
"""
【チェック観点】
1. インボイス制度対応(適格請求書要件)
2. 数値の整合性(小計×税率=消費税額、合計の一致)
3. 必須項目漏れ(発行者登録番号・発行日・取引内容・金額・税率区分)
4. 記載ミスの可能性が高い箇所
5. 取引先からクレームになりそうな曖昧表現
数字の検算は計算式とともに示してください。経理13:月次レポート要約
以下の月次試算表を要約してください。
【試算表】
"""
[勘定科目別の月次データ]
"""
【出力】
1. 経営者が3分で把握すべき3つのポイント
2. 前月比/前年同月比で異常値があった項目(理由仮説3つ)
3. キャッシュフロー上の注意点
4. 次月までに確認すべき5項目(経理→経営者報告)
5. 数字を可視化する推奨グラフ3つ
数字の解釈には複数の可能性を示し、決めつけない表現にしてください。経理14:契約書の財務リスクチェック
以下の契約書ドラフトを財務リスク観点でチェックしてください。
【契約書】
"""
[契約書本文]
"""
【チェック観点】
1. 支払条件(前払/分割/後払、サイト日数)の財務インパクト
2. 損害賠償・違約金の上限
3. 解約時の精算ルール
4. 価格改定条項の有無
5. 為替・税制変動への対応条項
6. 検収・支払遅延時のペナルティ
リスクレベル(高/中/低)と推奨修正文を併記してください。
最終判断は税理士・顧問弁護士に必ず確認するよう一文添えてください。経理15:補助金・助成金申請書作成支援
以下の補助金申請に向けて、申請書のドラフトを作成してください。
【補助金名】[名称・公募回]
【自社情報】[業種・規模・売上]
【申請したい用途】[設備投資/IT導入/研修など]
【想定経費】[内訳]
【出力】
1. 事業計画書の本文ドラフト(3,000字程度)
2. 申請書類チェックリスト
3. 審査員に響く差別化ストーリー3案
4. よくある不採択理由と対策
ただし、最終的な数値・固有名詞・要件適合は公募要領を確認し、必ず社労士・行政書士の監修を受けてください。カテゴリ4:人事(プロンプト16〜20)
人事16:求人票作成
以下の条件で求人票を作ってください。
【ポジション】[職種]
【会社概要】[業種・規模・カルチャー]
【業務内容】[具体的なタスク5点]
【求めるスキル】[必須/歓迎]
【条件】[年収レンジ・働き方]
【出力】
1. キャッチコピー(30字以内、ありきたりNG)
2. 仕事の魅力(500字、現職者の声風)
3. 業務内容(箇条書きで明確化)
4. 求める人物像(スキル+価値観)
5. 条件・福利厚生
6. 採用プロセス
7. よくある質問3問
差別表現・年齢限定・性別限定など法令違反になる表現は使わないでください。関連: AI求人票・スカウト文作成
人事17:1on1議事録整形
以下の1on1メモを構造化してください。
【メモ】
"""
[走り書きのメモを貼り付け。個人情報は記号化推奨]
"""
【出力】
1. 議題サマリ(3行)
2. 本人の現状(業務/関係性/モチベーション)
3. 課題と原因の仮説
4. 合意したアクション(本人/上司、期限つき)
5. 次回1on1までのフォロー事項
6. 上司として注意すべき発言シグナル(離職リスク等)
ただし離職判断や評価への直結はせず、人事担当との対話を推奨する一文を添えてください。人事18:研修プログラム設計
以下の研修プログラムを設計してください。
【対象】[新入社員/中堅/管理職]
【人数】[N名]
【時間】[半日/1日/2日]
【目的】[スキル習得/カルチャー浸透/相互理解]
【予算感】[ハイ/ミドル/ロー]
【出力】
1. 研修ゴール(学んだ翌日に何ができるか)
2. タイムテーブル(5-10分単位)
3. 各セッションの狙い・形式(講義/ワーク/ディスカッション)
4. 必要な事前準備(教材・資料・備品)
5. 評価方法(理解度テスト/アンケート/行動変容)
6. 当日のリスク3つと対応策人事19:360度フィードバック集約
以下の360度フィードバック回答(複数名)を集約してください。
【対象者】[役職・所属]
【回答者数】[N名、立場の内訳]
【生回答】
"""
[匿名化された回答を貼り付け]
"""
【出力】
1. 強み(複数回答者が共通して挙げた点)
2. 改善期待領域(同上)
3. 矛盾する評価(人によって違う見方が出た点)
4. 本人へのフィードバック原稿(500字、敬意ある表現)
5. 注意:誰が言ったか特定できる表現は避ける
辛辣な表現を本人原稿に直訳しないでください。意図を保ちつつ建設的に変換してください。人事20:就業規則の質問対応
以下の社員からの質問に、就業規則の該当条項を引用しながら回答してください。
【質問】[質問内容]
【就業規則の該当部分】
"""
[該当条文を貼り付け]
"""
【出力】
1. 結論(簡潔に、まず1行で)
2. 該当条項の引用と解説
3. 想定される例外ケース
4. 上司・人事への確認推奨ポイント
5. 法令との整合性チェック(労働基準法・育児介護休業法等)
ただし、最終判断は社労士または労働基準監督署への確認を推奨してください。カテゴリ5:カスタマーサポート(プロンプト21〜25)
CS21:問い合わせ一次回答テンプレ生成
以下の問い合わせに対する一次回答を作ってください。
【問い合わせ内容】
"""
[顧客からのメール/チャット原文]
"""
【自社サービス情報】[該当機能・FAQ]
【顧客属性】[初回/既存、温度感]
【出力】
1. 推奨回答(300字以内、丁寧かつ的確)
2. 確認すべき追加情報3点
3. エスカレーション要否判断(Yes/No と理由)
4. 類似問い合わせを減らすためのFAQ追加候補(200字)
5. クレームに発展するリスク評価(低/中/高)CS22:クレーム対応文面
以下のクレームに対する一次対応メールを作ってください。
【クレーム内容】
"""
[原文]
"""
【経緯】[時系列で]
【こちらの非の所在】[明確/不明/争点あり]
【出力】
1. 謝罪文(言い訳に聞こえない、500字以内)
2. 事実確認のための質問3点(追い詰めない表現)
3. 想定される落とし所3パターン(顧客満足度別)
4. 社内記録用の事実整理
5. SNS拡散リスクの評価
法的論点が含まれる場合は、必ず弁護士確認を推奨する一文を入れてください。CS23:FAQ整理
過去1ヶ月の問い合わせログを分析してFAQを整理してください。
【問い合わせログ】
"""
[個人情報をマスクしたログを貼り付け]
"""
【出力】
1. 頻出問い合わせTOP10(件数推定)
2. 各FAQの推奨回答(200-300字)
3. プロダクト改善で根本解決できそうな問い合わせ3件
4. ヘルプページ構成の改善提案
5. CSの工数削減見込み(推定)CS24:チャットボットシナリオ設計
以下のサービス向けにチャットボットの会話シナリオを設計してください。
【サービス】[概要]
【主要問い合わせ】[TOP5]
【オペレーター人数】[N名・稼働時間]
【出力】
1. 初回応答メッセージ(30字以内、距離感重要)
2. 5つの主要分岐(問い合わせカテゴリ)
3. 各分岐の応答ツリー(3階層まで)
4. オペレーター連携トリガー条件
5. 営業時間外応答メッセージ
6. 顧客満足度を下げないトーン例CS25:解約防止リテンションメッセージ
解約予兆のある顧客に送るリテンションメッセージを作ってください。
【顧客状況】
- 利用期間: [期間]
- 利用頻度の変化: [低下傾向]
- 過去の問い合わせ: [内容]
【サービス側で打てる手】[割引/機能追加/サポート強化]
【出力】
1. メッセージ案3パターン(押し付け感ゼロ)
2. 提案する解決策(無理に引き留めない)
3. 解約手続きへの誘導も併記(信頼を失わない)
4. 解約後の再契約導線
5. 解約理由ヒアリングの聞き方カテゴリ6:企画・経営(プロンプト26〜30)
企画26:新規事業アイデア発散
以下の制約条件で新規事業アイデアを発散してください。
【自社の強み】[3つ]
【活用したい既存資産】[人材/技術/顧客基盤]
【投資できる金額】[範囲]
【3年後の売上目標】[金額]
【出力】
1. アイデア15個(粒度バラバラでOK、まず量)
2. 各アイデアの市場規模仮説
3. TOP5に絞り込んだ理由
4. TOP3それぞれのMVP案
5. やらない方がいい理由が立ちそうなアイデア3個(早期撤退判断用)
数字はすべて推定であることを明記してください。企画27:会議の議論を構造化
以下の会議メモを構造化してください。
【メモ】
"""
[議論メモを貼り付け]
"""
【出力】
1. 議論の主軸テーマ
2. 賛成派の主張(要約と論拠)
3. 反対派の主張(要約と論拠)
4. すり合わせ可能な論点と平行線の論点の区別
5. 次回までに集めるべきデータ・調査事項
6. 意思決定のための推奨フレームワーク(RACI/ICE/SWOTなど)関連: AI会議効率化の実務
企画28:タスク優先度判定
以下のタスクリストを優先度順に並び替えてください。
【タスク一覧】
"""
[20-50個のタスクを貼り付け]
"""
【判定軸】
- 緊急度(締切まで)
- 重要度(経営目標への寄与)
- 工数(軽い/中/重い)
- 依存関係(他タスクの前提)
【出力】
1. 緊急×重要マトリクスでの分類
2. 上位10タスクの推奨着手順
3. 委任可能なタスク(誰に任せるか案)
4. 削除候補のタスク(やらない判断)
5. ボトルネックになりそうなタスク関連: AIタスク優先度判定の実務
企画29:KPIダッシュボード設計
以下の事業のKPIダッシュボードを設計してください。
【事業概要】[BtoB SaaS/小売/受託など]
【売上規模】[年商]
【現状の課題】[3つ]
【出力】
1. North Star Metric(NSM)の候補3つ
2. NSMを構成するサブ指標5-7個
3. 日次/週次/月次で見るべき指標の区別
4. ダッシュボードの推奨レイアウト
5. 異常値検知の閾値
6. 役員報告に使える1枚サマリの構造企画30:競合・市場分析レポート
以下のテーマで市場・競合分析レポートを作ってください。
【市場】[業界・セグメント]
【自社の現在位置】[シェア・強み]
【主要競合】[3-5社]
【調査目的】[新規参入/拡大/防衛]
【出力】
1. 市場サマリ(規模・成長率・主要プレイヤー)
2. 競合各社のポジショニングマップ
3. 自社のSWOT分析
4. 想定される市場変化シナリオ3つ
5. 推奨戦略3案(守り/攻め/転換)
6. 必要な追加調査リスト
数字は推定値であることを明記し、必ず一次ソース確認を推奨してください。5. プラグイン・GPTs・Operator・Atlas の使い分け
ChatGPTには2026年5月時点で4つの拡張機能があります。それぞれの違いを「中小企業が業務で使うなら」という観点で整理します。
| 機能 | 何ができるか | 中小企業での使いどころ | 注意点 |
|---|---|---|---|
| GPTs(カスタムGPT) | 自社専用のChatGPTを作成・社内共有 | FAQ応答、社内用語辞書、定型業務テンプレ | 機密プロンプト・データの管理ルール必須 |
| プラグイン(旧)→ アプリ連携 | Slack/Google Drive/Salesforce等と接続 | 社内ツールと統合した検索・要約 | Business以上推奨、権限設定が要 |
| ChatGPT Agent(旧Operator) | ブラウザ操作の自動化(クリック・入力・スクレイピング) | 定型レポート取得、競合価格モニタ | Plus以上、料金体系と上限公式サイトで最新情報をご確認ください |
| Atlas(ブラウザ) | OpenAI製ブラウザ、ChatGPT統合済 | 調査作業の効率化、コンテキスト継続 | 2025年下期リリース、安定性検証中 |
事例区分: 想定シナリオ
100社以上の研修経験から見た典型例として、最も成果が出やすいのは「GPTsで部門別カスタムGPTを3〜5個作る」運用です。営業GPT・経理GPT・人事GPT・CS GPTを作り、各部門が「自分専用の業務アシスタント」を持つ形にすると、プロンプトを毎回ゼロから書く負担が減り、現場の利用継続率が大幅に上がります。
6. セキュリティと運用ルール(学習データ・個人情報・幻覚率)
ChatGPTを企業導入する際、最大の不安は「機密情報や個人情報が学習データに使われないか」と「幻覚(事実誤認)への対処」です。2026年5月時点の実務ルールを整理します。
セキュリティ運用5原則
- 機密度別のプラン選定:機密データを扱うならBusinessまたはEnterprise(デフォルトで学習除外)。Plusで使うなら設定画面で「Improve the model for everyone」を必ずOFFにする。
- 個人情報マスキングのルール化:氏名・住所・電話・メール・口座番号・マイナンバーは投入前にマスク([顧客A]、[電話番号]等に置換)。マスキングを自動化するChrome拡張も活用検討。
- 幻覚率86%を前提とした人間レビュー必須化:GPT-5.5は推論能力こそ高いが幻覚率は依然86%(Claude Opus 4.7=36%)。法務・財務・医療・人事評価などの高責任業務は、必ず人間が最終確認する運用に。
- ログ保存と監査:BusinessではAdmin Consoleで利用ログを集約可能。誰が何を聞いたか定期監査する。
- 禁止業務リストの明文化:「ChatGPTに投げてはいけない業務」を社内規程で明示。例:採用合否判定の最終文書化、医療診断、法的助言の最終回答、未公開M&A情報の処理。
関連法令・ガイドライン
- 個人情報保護委員会「OpenAIに対する注意喚起」(2023年6月)— 国内法令遵守義務、要配慮個人情報の取扱注意
- 総務省・経産省「AI事業者ガイドライン」(第1.0版)— 中小企業も意識すべき10原則
- OpenAI公式「Enterprise privacy at OpenAI」— データレジデンシー・SOC 2 Type II
戦略レベルでの統合はAI導入戦略ガイド、AIエージェント運用全般はAIエージェント導入完全ガイドを参照してください。
7. ChatGPT vs Claude vs Gemini — 中小企業の選び方
「ChatGPTだけで完結しますか?」も研修先で頻出の質問です。結論から言うと、2026年5月時点では「メインChatGPT、機密度の高い10〜20%の業務でClaude、画像・動画解析でGemini」という3本立てが中小企業の最適解です。

| 用途 | 推奨 | 理由 |
|---|---|---|
| 提案書・社内文書・調査 | ChatGPT(GPT-5.5) | 速度・コスト・連携機能のバランス |
| 法務・財務の精査、コード生成 | Claude(Opus 4.7) | 幻覚率の低さ、長文の論理整合性 |
| 画像・動画・音声の解析 | Gemini 3.1 Pro | マルチモーダル処理の強さ |
| 大量テキスト要約(100万字超) | ChatGPT or Gemini | 1Mトークン文脈長 |
| 機密度MAXの業務 | Claude Enterprise | HIPAA対応・データレジデンシー |
3モデルの詳細比較はGPT-5.5 vs Claude Opus 4.7 vs Gemini 3.1 Pro ビジネス比較で。Claude単体の導入論は中小企業向けClaude導入ガイド、Anthropic側のインフラ動向はAnthropic×SpaceX Colossus契約とClaude上限緩和を参照。
8. 【要注意】ChatGPT導入の失敗パターン4選
失敗1:Freeプランで全社展開しようとして停滞
❌ 「とりあえずFreeで全員試してみよう」
⭕ 「キーマン5名にBusinessを配布、3ヶ月後に全社展開判断」
なぜ重要か:Freeはレートリミット・機能制限・学習データ除外の手動設定が必要で、企業利用には不向き。最初から少人数Businessで「業務に効く」体感を作ることが定着の鉄則です。
失敗2:個人情報・機密情報をそのまま投げる
❌ 顧客名簿・契約書・社員評価をPlusに直接ペースト
⭕ Business以上 + マスキングルール明文化
なぜ重要か:個人情報保護法・取引先との秘密保持契約に違反するリスク。実際に研修先(製造業・従業員150名)で発覚し、社内規程の事後整備に2ヶ月を要しました。最初に運用ルールを作ることで防げます。
失敗3:プロンプトのコピペ依存で「使いこなしている錯覚」
❌ 30個のプロンプトを配布して終わり
⭕ プロンプトを「自分の業務文脈に書き換える研修」までやる
なぜ重要か:他社のプロンプトをそのまま使うと、自社の用語・前提が抜けて出力品質が落ちます。研修先の小売チェーンで「営業プロンプトを全店配布したが2ヶ月後の利用率2%」だった例があります。プロンプトはテンプレ、文脈は自分で埋める。
失敗4:評価指標なしの導入で経営判断不能に
❌ 「便利だね」だけで終わり、ROIが見えない
⭕ 業務時間削減・売上寄与・問い合わせ数等のKPIを最初に定義
なぜ重要か:3〜6ヶ月後に「結局効果あったの?」と経営から聞かれて答えられないと、契約打ち切りになります。導入時に「何を測るか」を必ず決めてください。
9. 導入5ステップ — 小さく始めて全社展開まで
研修先・顧問先で実際に成果が出ている標準プロセスです。期間目安は中小企業(30-100名)想定。
ステップ1:小さく始める(Week 1-4)
- キーマン3-5名にBusiness契約
- 各人が「最も時間を取られている業務TOP3」を洗い出し
- 本記事のプロンプト30選から5本選んで毎日使う
- 週次で「何分削減できたか」を記録
ステップ2:チーム展開(Month 2-3)
- 成果が出た2-3業務を「GPTs」化(部門共有テンプレ)
- 対象チームを10-15名に拡大
- 週1回30分の「ChatGPT定例」で困りごと共有
- セキュリティ運用ルール(個人情報マスキング等)を明文化
ステップ3:部門展開(Month 4-6)
- 営業・マーケ・経理・人事・CSの主要部門に展開
- 部門GPTsを各部門担当者が作成・運用
- 月次レポートで利用ログとKPI(時間削減・売上寄与)を集計
- 失敗事例の社内共有会を月1回
ステップ4:全社展開(Month 7-12)
- 全社員にBusiness配布
- 新入社員研修にChatGPT基礎を組み込み
- 従業員50名超ならEnterprise移行検討
- Admin Consoleで利用ログを定期監査
ステップ5:KPI運用と高度化(Year 2-)
- 業務時間削減のROI試算を経営会議に定例化
- Claude/Geminiとの併用設計
- AIエージェント(自動実行)への移行を検討
- 競合がやっていない業務領域への展開
10. ROI試算の考え方 — 人件費換算・時間削減・売上貢献
「結局いくら儲かるんですか?」これも経営者から必ず聞かれます。ChatGPTのROIは3つの軸で試算します。
軸1:人件費換算(最も計算しやすい)
従業員1人あたりの時間単価を3,000円とすると、1日30分の業務削減=月1.5万円 × 12ヶ月=年18万円。Business $20/月(年$240、約3.6万円)に対し、ROI約5倍。30名で導入すれば年540万円の人件費換算効果。
軸2:売上貢献(測定しにくいが効果大)
営業の提案書作成時間が4時間→1.5時間に短縮されると、月の提案件数が1.5〜2倍に。受注率を変えずとも売上は1.5倍以上に伸びる試算が成立します。研修先の専門商社で実測値として確認しています。
軸3:機会損失の回避(経営インパクト最大)
クレーム対応の初動が遅れて炎上したケース、競合との差別化トーク準備不足で失注したケース。これらの「やらなかったコスト」をChatGPT活用で減らせる。試算は難しいですが、経営者向けには「失注1件あたりのコスト × 削減見込み件数」で説明すると刺さります。
11. よくある質問(FAQ・8項目)
Q1:ChatGPT Plus $20を個人で契約して業務に使ってもいいですか?
A:機密情報を扱わない範囲なら問題ありませんが、社内データ・顧客データを投入するならBusiness以上を会社契約してください。個人Plusは学習除外が手動設定で漏れリスクがあります。
Q2:GPT-5.5とGPT-5の違いは体感できますか?
A:明確に体感できます。長文文書(1万字超)の要約・整合性チェック、コード生成、エージェント的なタスク実行で差が出ます。逆に短い文書生成・翻訳ではほぼ違いを感じません。
Q3:日本語性能はGPT-5.5で改善されましたか?
A:はい。特に長文の論理展開・敬語の自然さ・業界用語の正確さで改善が見られます。ただし固有名詞(地名・人名)の幻覚は依然残るため、ファクトチェックは必須です。
Q4:Codex(コード生成)は誰が使うべきですか?
A:エンジニア部門と、Excel/Google Sheets自動化を進めたい経理・営業企画が使うと効果大。料金体系はCodex料金完全ガイドを参照。CLI最新動向はCLI 2026年4月アップデートで。
Q5:ChatGPT Agent(旧Operator)はもう実用に耐えますか?
A:定型レポートの取得・競合価格モニタなど「定形作業」では実用レベルに到達しました。ただし複雑な判断を含むタスクではまだ人間レビュー必須です。
Q6:Edu/教員向けの無料枠は中小企業も使えますか?
A:使えません。教員向けは米国K-12教員(2027年6月まで)が対象。Eduプランは大学契約専用です。
Q7:何人から有償プランに切り替えるべきですか?
A:2名以上の業務利用で即Business推奨です。Plusを複数アカウント分契約するより、Businessの方がコスト・管理・セキュリティすべて優位です。
Q8:解約しても作成したGPTsやデータは残りますか?
A:解約後一定期間はアーカイブされますが、業務継続性を考えるとエクスポート手順を最初に決めておくべきです。重要なGPTsプロンプトはGoogle Driveなど別途バックアップ。
業種別 ChatGPT活用の勘所(10業種早見表・Uravation独自)
ここまでは営業・経理・人事といった「部署軸」で見てきましたが、実際の効きどころは業種によっても大きく変わります。同じ「文書作成」でも、製造業なら作業手順書、不動産なら物件紹介文、医療なら患者向け説明文と、求められる型と注意点がまったく違うからです。下表は、Uravationが100社以上の導入支援で見てきた「業種ごとに最初に効く使い方」と「踏んではいけない落とし穴」を1枚にまとめた早見表です。各業種の詳しい手順は、リンク先の専門ガイドで解説しています。
| 業種 | 最初に効く業務 | ChatGPT活用例 | ここは人が確認 | 詳しい手順 |
|---|---|---|---|---|
| 製造 | 報告書・手順書・議事録の文書化 | 日報から週報への要約、作業手順書のたたき台づくり | 図面・寸法・品質基準は担当者が確認 | 製造現場のAI活用事例 |
| 小売・飲食 | シフト作成・販促文・口コミ返信 | 勤務表のたたき台、POP・SNS文案、レビュー返信 | 在庫・人件費・最終的なシフトは人が判断 | シフト作成の自動化ガイド |
| 不動産 | 物件紹介文・査定コメント・問い合わせ返信 | 物件キャッチコピー、内見案内文、メール返信の下書き | 価格・法令表示・重要事項は宅建士が確認 | 不動産DXの始め方 |
| 医療(クリニック) | 院内文書・患者向け説明文・予約案内 | 受付FAQ、検査・処置の説明文の下書き | 診断・治療はAI不可。患者の個人情報は入力しない | クリニックのAI活用事例 |
| 建設・工務店 | 見積書・提案書・現場報告の整理 | 見積項目の整理、提案書ドラフト、現場日報の清書 | 数量・単価・積算は担当者が確認 | 工務店AI活用15選 |
| 物流 | 配送メモ・マニュアル・問い合わせ対応 | 配送指示の整理、業務手順書(SOP)作成 | 実運行データ・取引先情報は入力しない | 物流・SCMのAI活用動向 |
| 金融・保険 | 商品説明文・FAQ・社内文書 | 保険商品の説明下書き、よくある質問の整備 | 募集文言・表示・コンプラは専門部署が確認 | 保険業界のAI活用ガイド |
| 教育・研修 | 教材・eラーニング・案内文の作成 | 研修コンテンツのたたき台、受講案内メール | 事実・出典・専門内容は人が検証 | 研修コンテンツ内製ガイド |
| 士業(社労士など) | 労務文書・案内・FAQ | 就業規則の説明文、顧問先への案内メール | 法的判断・申請・作成代理は有資格者が確認 | 社労士事務所のAI活用 |
| オフィス共通 | メール・議事録・資料作成(営業/経理/人事) | 本記事の「業務別プロンプト30選」を参照 | 機密・個人情報は入力しない | (本記事内で解説) |
業種が違っても、共通する原則は3つです。①最初は「文書化・たたき台づくり」から始める(判断業務は後回し)、②機密情報・個人情報は入力しない、③AIの出力は必ず人が最終確認する。この3点さえ守れば、どの業種でもリスクを抑えながら成果を出せます。自社の業種で「どの業務から始めるべきか」を具体的に設計したい場合は、上記の専門ガイドとあわせて、無料相談もご活用ください。
12. 関連記事ナビ — ピラー・スポーク・カテゴリ別
ピラーページ(兄弟):
- AIエージェント導入完全ガイド — エージェント全般の体系
- AI導入戦略ガイド — 経営戦略レイヤー
モデル比較・選定:
- GPT-6 Spudリリース動向|企業の準備3ステップ
- GPT-5.5 vs Claude Opus 4.7 vs Gemini 3.1 Pro ビジネス比較
- 中小企業向けClaude導入ガイド
- Anthropic×SpaceX Colossus契約とClaude上限緩和
Codex・コード生成:
業務別ノウハウ:
13. まとめ:今日から始める3つのアクション
- 今日やること:本記事の「営業1:提案書ドラフト一括生成」プロンプトを1本、自分の現業務で試す。所要15分。「思ったより使える」を体感する。
- 今週中:Business契約を3-5名分で開始(既にPlus契約しているならBusinessにアップグレード)。同時に「自部門の最も時間を取られているTOP3業務」をリストアップし、対応プロンプトを本記事30選から選定する。
- 今月中:GPTsで自部門用カスタムGPTを1個作成し、チーム内3-5名で共有運用を開始する。月末に「業務時間削減ログ」を集計し、経営報告できる形に整える。
次回予告:次の記事では「GPTs実践構築ガイド — 業務別カスタムGPT 10選」をテーマに、本記事の30プロンプトをGPTs化して全社運用に乗せる具体手順をお届けします。
ChatGPT・業務AI活用の深掘り記事 55選
部署別・業務別の活用パターンと、関連ツール(Notion AI / Claude Design / 業界別AI)の解説記事です。
ChatGPT・OpenAI最新動向と活用(35本)
- GPT-5.5 Instantとは?企業AI運用の新標準と導入アクション
- 中堅EC事業者がChatGPT Businessを始める3ヶ月の手順
- Notion AI 完全活用【2026年11月】部署別30プロンプト・料金・始め方 実例ガイド
- 資料作成でClaude Designを始める手順|30選
- 不動産業AI活用 業態別深掘りガイド
- 【2026年5月速報】GPT-5.5 Instant徹底解説|幻覚52%減と新メモリ機能の衝撃
- 【2026年最新】AIで動画台本・YouTubeシナリオを作る|伝わる構成5プロンプト
- 社内ナレッジ散逸をClaude Memoryで解決する方法
- 【2026年最新】GPT-5 Voice実装|WebSocket・VAD・コスト
- DeepSeek V4完全ガイド|GPT-5.5の8.6倍安い新フロンティア
- 【2026年最新】AI導入の稟議を通す方法|予算承認を得る5プロンプト
- OpenAI 1100億ドル調達の内訳|3社の狙いとIPOへの道
- 【2026年最新】Snowflake×OpenAI提携|AIが同僚になる日
- 【2026年4月速報】Novo Nordisk×OpenAI全事業AI統合
- 【2026年最新】ChatGPTダウン対策|企業のAI BCP設計
- AI研修プロンプト集50選|部署別テンプレ公開
- 【速報】ChatGPTに広告表示開始|無料・GoプランとOpenAI収益化戦略
- 司法書士が登記・相続業務をAIで効率化する手順|プロンプト15選
- ChatGPTで提案書を作る方法|受注率が上がる15プロンプト
- 【2026年最新】学生向けAI比較|ChatGPT・Claude・Gemini
- Claude図解生成の業務活用|コピペで使えるプロンプト15選
- 【2026年4月速報】OpenAI社会契約ブループリント全解説
- OpenAI $1220億調達の衝撃|AI投資の新時代と企業戦略
- AI障害時の対応マニュアル|Claude・ChatGPT・Gemini代替手段
- 旅行代理店にAI導入は本当に必要か|判断3軸とプロンプト15選
- 【2026年最新】AIで与信管理・取引先信用調査|中小企業がリスクを減らす5ステップ+7プロンプト
- GPT-5.4でExcel経理を自動化するプロンプト10選
- 【2026年速報】ChatGPT広告6週で1億ドル|CPM 60ドル
- 【2026年最新】AIで競合分析・市場調査|仮説出しを加速する5プロンプト
- OpenAI Enterprise売上40%突破|BtoB主戦場
- DeepSeek V4 完全ガイド【2026】|性能ベンチ・料金・GPT-5比較
- 【2026年最新】AIでウェビナー集客・運営|企画から事後フォローまで5ステップ+7プロンプト
- GPT-5.3 Codex は『Daily Work Agent』に進化|Interactive Steering と非エンジニアの業務エージェント活用法【2026】
- 【Q2予測】GPT-6・Claude 5・Llama 4|3モデル同時の備え方
- GPT-5.4 Computer Use|OSWorld 75%超RPA置換
業務別AIプロンプト・実践テンプレ(4本)
- AI営業支援SaaSの選び方|既存システム別の最適解と料金【2026年最新】
- Gemini Chrome Enterprise|ブラウザ業務を自律AI化
- AI時代のコンテンツマーケ戦略の選び方|5軸
- AI歴史動画の作り方|Kling 3.0でタイムトラベルPOV量産
AIツール深掘り(Notion AI / Claude Design 他)(16本)
- News Corp×Meta .5億|AI学習契約の新関係
- 【2026年4月速報】DARPA MATHBAC|AIエージェント通信の数学基盤
- 【2026年4月速報】HumanX 2026全解説|デモ止まり終焉
- 【2026年最新】MSRAのAgentic AI研究|人間-AI協働の未来設計図
- Claude Opus 4.7完全ガイド|Sonnet 4.6・料金比較
- 【2026年速報】Box社でOpus 4.7がモデル呼び出し56%削減を実現
- 【2026年2月速報】Eli Lilly LillyPod|AI 9000PF
- 【2026年5月】Claude 9コネクタ解説|Blender・Adobe連携
- 1週間で4社がAIエージェント基盤を発表した意味
- 【2026年4月最新】Mythos Preview|全OS脆弱性自律発見の衝撃
- Anthropicが米軍から排除された理由|日本企業への影響と対策
- 【2026年4月速報】HumanXで「Claude mania」勃発
- 【2026年最新】Gartner予測|企業アプリの40%がAIエージェント搭載へ
- Claude Code研修×助成金|最大75%OFF申請法
- 【2026年3月】Claude Code新機能|音声・定期実行・コスト制御活用法
- 【2026年最新】Claude Code GitHub連携完全ガイド|PR・Issue・Actions自動化7パターン
参考・出典
- Introducing GPT-5.5 — OpenAI公式発表(OpenAI、参照日: 2026-05-25)
- ChatGPT Plans — Free, Go, Plus, Pro, Business, Enterprise(OpenAI、参照日: 2026-05-25)
- ChatGPT Pricing for Business(OpenAI、参照日: 2026-05-25)
- 生成AIサービスの利用に関する注意喚起等について(個人情報保護委員会、参照日: 2026-05-25)
- AI事業者ガイドライン(第1.0版)(総務省・経済産業省、参照日: 2026-05-25)
- 中小企業のデジタル化・AI活用実態調査(中小企業庁、参照日: 2026-05-25)
- Microsoft 365 Copilot Overview — Microsoft公式(参照日: 2026-05-25)
- ChatGPT Plans Compared 2026(IntuitionLabs、参照日: 2026-05-25)
著者:佐藤傑(さとう・すぐる)
株式会社Uravation代表取締役。X(@SuguruKun_ai)フォロワー約10万人。
100社以上の企業向けAI研修・導入支援。著書『AIエージェント仕事術』(SBクリエイティブ)。
SoftBank IT連載7回執筆(NewsPicks最大1,125ピックス)。
ご質問・ご相談はお問い合わせフォームからお気軽にどうぞ。
ChatGPTエージェントモード 業務別7活用シナリオ — Workspace Agentsで「指示したら終わる」業務を作る
「ChatGPTを使っている」と「ChatGPTエージェントモードを使っている」は、もはや別の次元の話です。2026年4月22日にOpenAIがリリースしたWorkspace Agentsは、従来の「質問して回答をもらう」ChatGPTから、「仕事を丸投げしたら自律的にやり遂げる」ChatGPTへの根本的な変化を意味します。
研修現場で最近よく聞くのが「エージェントって怖くないですか?勝手に何かされたら」という声です。正直、気持ちはわかります。私も最初の3週間は慎重に使いました。でも実際に動かしてみると、Workspace Agentsは「完全自律」ではなく「承認ゲートを挟みながら自律」という設計になっており、許可した範囲でしか動かない。むしろ「止める場所が設計されている」点がビジネス利用に向いているんです。
Workspace Agentsの基本仕様(2026年6月時点)
| 項目 | 内容 |
|---|---|
| 利用可能プラン | Business・Enterprise・Edu(Plus/Pro/Goでは使用不可) |
| 課金方式 | クレジットベース(2026年5月6日以降、無料プレビュー期間終了) |
| 主な連携先 | Gmail・Slack・Linear・Notion・Google Drive・Salesforce他 |
| 実行環境 | OpenAIクラウド(ローカルファイルは不可、ガードが強め) |
| 承認モード | アクションごとに承認ゲートを設定可能(全自動〜都度確認まで選択) |
| テンプレート | 顧客返信・営業サポート・タスク管理など多数 |
詳細な使い方・料金・セットアップ手順はChatGPTエージェントモード完全ガイド2026に全部まとめています。本セクションでは「具体的にどの業務に使えば成果が出るか」の7シナリオに絞って解説します。
業務別7活用シナリオ
シナリオ1:問い合わせメールの一次返信(CS・営業)
Gmailと連携し、受信した問い合わせメールを読んで「返信ドラフト → 担当者承認 → 送信」のフローを自動化します。完全自動送信ではなく「担当者がOKを押したら送信」の承認ゲート設定が鍵です。
効果目安:一次返信のドラフト作成時間が1通5〜10分→30秒程度に。返信速度が3〜5倍に改善。
【Workspace Agentsへの指示テンプレ】
# 問い合わせ一次返信エージェント
## 役割
問い合わせメールを読んで、自社のFAQ・対応方針に基づく返信ドラフトを作成する。
## ルール
- FAQ文書(添付)を最優先参照
- 不明な内容は「担当者が確認してご連絡します」と書く
- 返信は200字以内を目安
- 作成後、必ず私([担当者名])の承認を取ってから送信する
## 連携ツール
- Gmail(受信トレイ監視)
- [FAQ文書のURL/ファイル]シナリオ2:議事録の要約・アクション展開(全部門)
ZoomやGoogle Meetの自動文字起こしをNotionに貼り付けると、Agentが要約・アクション抽出・担当者割り当て・LinearやSlackへの通知まで一気通貫で処理します。
実測値(顧問先の法人営業チーム7名):議事録整理・アクション展開の所要時間が20〜30分/回→3〜5分/回に短縮(測定:2026年4月〜5月、10回の会議で計測)。
シナリオ3:週次レポートの自動生成(マーケ・経営企画)
GA4・Slack・Notionのデータを毎週月曜日に集約し、「先週のトピック・KPI・次週の重点アクション」を1ページにまとめてSlackに投稿するまでをエージェントに任せます。定型集計業務の「人がやらなくてよい部分」を確実に排除できる用途です。
シナリオ4:競合価格・動向モニタリング(営業・マーケ)
競合企業のWebサイト・プレスリリースを定期スキャンし、価格変更・新機能リリース・重要ニュースを検知したらSlackに通知します。営業担当者が「週1回競合サイトを見て回る」時間を完全に削減できます。
シナリオ5:採用スカウトメールの一次作成(人事)
LinkedInやBizReachの候補者プロフィールと求人票を入力すると、候補者の経歴に合わせたカスタマイズスカウト文を自動生成します。人事担当者は「文章を書く」から「文章をチェックして送る」にシフトします。
シナリオ6:社内問い合わせ対応(IT・人事・総務)
社内FAQドキュメントをGoogleドライブに整備しておき、Slackで飛んでくる「有給申請どうやるの?」「Wi-Fiパスワード何?」的な定型質問に自動回答させます。IT部門・総務部門の問い合わせ対応が週数時間単位で削減できます。
シナリオ7:経費精算の前処理(経理・バックオフィス)
写真で撮った領収書をGmailに転送すると、OCR処理→金額・日付・用途の構造化→経費管理ツールへの入力ドラフト作成まで自動化します。精算担当者は「入力する人」から「確認する人」に変わります。
使う前に決めておくべき「承認ゲート設計」
Workspace Agentsで最も重要なのは「どのアクションに承認ゲートを挟むか」の設計です。やりがちな失敗は「全部自動にしてみたら、想定外のメールが顧客に送られた」というケースです。以下が実務で使える承認ゲートの3段階設計です。
| リスクレベル | アクション例 | 推奨設定 |
|---|---|---|
| 低(内部処理) | データ集計・要約・ドラフト作成 | 全自動OK(承認不要) |
| 中(社内通知) | Slack投稿・Notion更新・社内カレンダー登録 | 初回のみ承認、以降自動 |
| 高(外部送信) | 顧客メール送信・外部API呼び出し・発注処理 | 毎回承認必須 |
事例区分: 想定シナリオ
100社以上の研修経験から見た典型的な落とし穴として、最初からリスク「高」のアクションを自動化しようとするケースがあります。まずリスク「低」の内部処理を3ヶ月運用して「このエージェントの判断基準を信頼できる」という実績を積んでから、段階的にリスクを上げていくのが確実です。
プロンプト:Workspace Agentsセットアップ指示のたたき台
以下の業務フローをWorkspace Agentsで自動化するための指示を作ってください。
【自動化したい業務】[業務名]
【頻度】[毎日/毎週/メール受信時]
【連携ツール】[Gmail/Slack/Notion/Googleドライブ など]
【インプット】[何を受け取るか]
【アウトプット】[何を出力・通知するか]
【承認ゲート】[どのアクションで人の確認を挟むか]
【例外処理】[想定外の入力が来た場合の動作]
出力:
1. エージェント名と役割の1文要約
2. ステップ別の処理フロー(最大6ステップ)
3. 各ステップの承認ゲート設定(自動/都度確認)
4. 想定される誤作動パターンと対策2個ChatGPT vs Codex vs Claude — 2026年6月最新の使い分けマトリクス
「結局、ChatGPTとCodexとClaude、どれを何に使えばいいんですか?」
これは2026年上半期で最も多く受けた質問です。特にOpenAIが2026年6月2日にCodexの大型アップデート(役割別プラグイン6種・Sites機能・アノテーション機能)を投入したあとから、「Codex単体でどこまでできるか」の認識がガラッと変わりました。同時にClaude Code(Anthropic)も進化し続けており、単純な「どれが一番か」比較ではなく「用途別に何を選ぶか」の設計が必要な時代になっています。
詳細なCodex 6月アップデートの内容はOpenAI Codex 6月大型アップデート完全解説に、料金・CLI比較の詳細はCodex CLI vs Claude Code 料金・機能徹底比較2026にまとめています。本セクションでは「ビジネス現場でどう使い分けるか」に絞って整理します。
2026年6月時点の3ツール基本比較
| 比較項目 | ChatGPT(GPT-5.5) | Codex(6月更新後) | Claude(Opus 4.7 / Code) |
|---|---|---|---|
| 主な強み | 汎用性・文書生成・エージェント(Workspace Agents) | コーディング・Sites生成・役割別プラグイン | 長文理解・精度・Claude Code(ターミナル作業) |
| SWE-bench Pro | GPT-5.5: 58.6 | Codex: SWE-bench類似ターミナルタスクで優勢 | Claude Code: フロントエンド4倍速(ダッシュボード構築比較) |
| 幻覚率(公開値) | GPT-5.5: 86%(OpenAI公表) | GPT系ベース | Claude Opus 4.7: 36%(OpenAI公表値と比較) |
| 文脈長 | 1Mトークン | 64K〜(用途依存) | 最大200Kトークン(Claude 3.7系) |
| 料金感 | Business $20-30/シート | ChatGPTプランに含む(クレジット消費) | Sonnet: コスパ高め / Opus 4.7: 高額 |
| 機密データ除外 | Businessなら自動除外 | Businessなら同様 | Claude.ai Business: 自動除外 |
業務別 使い分けマトリクス(Uravation独自・2026年6月版)
| 業務カテゴリ | 推奨1st | 推奨2nd | 理由 |
|---|---|---|---|
| 文書作成・メール・提案書 | ChatGPT | Claude | GPT-5.5の日本語自然さ + 高速生成が強み |
| コード生成・デバッグ(フロントエンド) | Claude Code | Codex | ダッシュボード構築で4倍速、UI品質でも優勢 |
| コード生成・デバッグ(ターミナル・CLI) | Codex | Claude Code | SWE-benchターミナルタスクでCodexに優位性 |
| 長文読解・契約書レビュー・精度重視 | Claude Opus 4.7 | ChatGPT | 幻覚率36% vs 86%の差が法務・財務で決定的 |
| 市場調査・競合分析 | ChatGPT | Claude | WebブラウジングとDeep Research機能が強み |
| Webアプリ・ダッシュボード生成 | Codex(Sites機能) | Claude Code | 6/2投入のSites機能で「作って即公開」が可能 |
| 自律タスク(エージェント) | ChatGPT(Workspace Agents) | Claude(Projects) | Workspace Agentsの外部連携網が豊富 |
| 社内文書・マニュアル整備 | ChatGPT | Claude | GPTs(カスタムGPT)で部門別に最適化しやすい |
2026年6月Codex大型アップデート:ビジネス担当者が知るべき3点
2026年6月2日にOpenAIが投入したCodexアップデートの内容は膨大ですが、ビジネス担当者(非エンジニア)に関わる変化は3点に絞られます。
①役割別プラグイン6種:マーケター、HR担当、財務担当など、エンジニア以外の職種向けにもCodexを使いやすくするプラグインが登場。これにより「Codex = エンジニアのツール」から「全職種のツール」への転換が進んでいます。
②Sites機能(プレビュー):ChatGPT Business・Enterpriseユーザー向けに、指示するだけでWebアプリ・ダッシュボード・ツールを作ってOpenAIのインフラ上に公開できる機能。「社内ダッシュボードを作りたいがエンジニアリソースがない」という中小企業には刺さる機能です。ただし2026年6月時点はプレビュー中で、Business・Enterpriseのみ利用可。
③アノテーション機能:生成コードの一部だけを指定して修正指示を出せる機能。「ここの計算ロジックだけ直して」という細かい指定ができるようになり、非エンジニアでも生成物を精緻に調整しやすくなりました。
判断フロー:「今どれを使うべきか」30秒チェック
| 状況 | 推奨 |
|---|---|
| 文書・メール・資料を今すぐ生成したい | ChatGPT(GPT-5.5) |
| 契約書・財務書類のレビューで精度最優先 | Claude Opus 4.7 |
| コードを書いてもらいたい(エンジニア) | Claude CodeとCodexを用途で使い分け |
| ノーコードでWebアプリを作って即公開したい | Codex(Sites機能、Business以上) |
| メール・Slack・Notionを横断した自律タスク | ChatGPT Workspace Agents(Business以上) |
| コスパ重視で汎用業務(10名以下の中小企業) | ChatGPT Business + Claude Sonnet(API)の2本柱 |
事例区分: 実案件(匿名加工)
顧問先のITサービス企業(従業員45名)で実際に行った導入設計では、「全社の文書業務 → ChatGPT Business」「エンジニアのコード生成 → Claude Code(フロントエンド)+ Codex(バックエンド・ターミナル)」「法務・契約書レビュー → Claude Opus 4.7(API経由)」の3層設計を採用しました。導入後3ヶ月で「誰もが同じツールを全業務に使っている」という状態から「業務の性質によってツールを使い分ける文化」に移行した事例です(測定期間:2026年2月〜4月)。
よくある失敗:「1ツール完結」の罠
❌ 失敗パターン1:ChatGPTしか使わないせいで、財務レビューの幻覚ミスが発覚(幻覚率86%の影響)
✅ 解決:機密度・精度要求の高い業務はClaude Opus 4.7を使う
❌ 失敗パターン2:Codexでフロントエンド開発しようとして、シンプルなダッシュボードに2時間かかった
✅ 解決:UIを含むフロントエンドはClaude Codeの方が4倍速いケースがある(Tom’s Guide比較2026)
❌ 失敗パターン3:全員にClaude Opus 4.7を導入したらコストが月15万円超えた
✅ 解決:Opus 4.7はハイリスク業務専用。汎用業務はClaude Sonnet(低コスト)かChatGPT Business
採用業務でChatGPTを活用する7パターン+ATS連携
「人事部門でAIを使いこなせている会社と、そうでない会社の差が2026年は特に広がっています」
これは先月、採用代行事業者の担当者から聞いた言葉です。実際、採用業務はAI活用の「実利が出やすい領域」のひとつです。文書作成(求人票・スカウト文・面接評価)の工数が大きく、かつ採用担当者の判断力を削ぐ「量をこなす業務」が多いからです。一方で、最終的な採用判断・候補者との関係構築は人間にしかできない。この「AIに任せる部分」と「人が担う部分」の切り分けが、採用AI活用の核心です。
採用業務全体の戦略については採用業務でAIを活用する完全ガイド2026で体系化しています。本セクションでは「ChatGPTを使って今週から変えられる7パターン」に絞って解説します。
採用業務 × ChatGPT 7パターン早見表
| パターン | 業務内容 | ChatGPTの役割 | 人が担う部分 | 難易度 |
|---|---|---|---|---|
| ①求人票作成 | JD(職務記述書)・求人原稿の作成 | ドラフト生成・求人サイト別フォーマット変換 | 内容確認・給与等の正確性チェック | ★☆☆ |
| ②スカウトメール個別最適化 | 候補者プロフィールに合わせた文章生成 | プロフィール読み込み → カスタム文生成 | 送信可否の判断・最終文面確認 | ★★☆ |
| ③面接質問設計 | ポジション別の面接ガイド・質問リスト | 職種・スキル要件から質問30〜50本を生成 | 自社文化に合わない質問の除外 | ★☆☆ |
| ④面接評価コメント整理 | 面接メモ → 構造化評価レポート変換 | 箇条書きメモを評価項目別に整形 | 点数付け・最終合否判断 | ★☆☆ |
| ⑤書類選考の一次フィルタ補助 | 応募書類の初期スクリーニング | 必要条件・歓迎条件の充足度チェック | 最終選考通過判断(必ず人が実施) | ★★★ |
| ⑥内定・不合格通知文の作成 | 候補者ごとの通知メール作成 | テンプレートに候補者名・選考内容を差し込み | 送信前の最終確認 | ★☆☆ |
| ⑦入社オンボーディング資料の整備 | 業務マニュアル・Q&A・社内ルール文書 | 口頭説明の文字起こしをガイド化 | 正確性確認・機密情報の除外 | ★★☆ |
プロンプト集:採用担当者がすぐ使える5本
採用プロンプト1:求人票のドラフト作成
以下の情報から求人票を作成してください。
【ポジション名】[職種名]
【雇用形態】[正社員/契約社員/パート]
【業務内容】
- [主な業務1]
- [主な業務2]
- [主な業務3]
【必須要件】
- [要件1]
- [要件2]
【歓迎要件】
- [要件1]
【給与・待遇】[金額・残業代・社会保険など]
【求める人物像】[自由記述]
【会社の雰囲気・文化】[自由記述]
出力:
1. タイトル(30字以内)
2. 求人概要(100字)
3. 業務詳細(500字)
4. 必須/歓迎要件(箇条書き)
5. 待遇・社風(200字)
求職者が「ここで働いてみたい」と思えるよう、具体的で誠実な文体で書いてください。数字は正確に記載し、不明な情報は「[公式サイトで最新情報をご確認ください]」と記載してください。採用プロンプト2:スカウトメールのカスタマイズ
以下の候補者プロフィールと求人情報を基に、スカウトメールを作成してください。
【候補者プロフィール】
現職:[現在の会社・役職]
経歴:[主な経歴・実績]
スキル:[技術スキル・言語・資格]
学歴:[最終学歴]
【求人情報】
ポジション:[職種]
期待する役割:[主な業務]
なぜこの候補者か:[マッチする理由]
出力:
件名(30字以内)
本文(200〜300字)
条件:
- 候補者の具体的な経歴・スキルに言及する(汎用テンプレ感を出さない)
- 「なぜあなたに連絡したか」を1文で明示する
- 押し売り感を出さず、まずは話を聞かせてほしいトーン採用プロンプト3:面接評価コメントの構造化
以下の面接メモを、採用評価シートに変換してください。
【面接メモ】
"""
[面接中のメモをそのまま貼り付け]
"""
【評価項目】
- コミュニケーション力
- 課題解決能力
- チームワーク・協調性
- 専門スキル・経験
- 志望動機・カルチャーフィット
出力形式:
各評価項目に対して
- 候補者の発言・態度から読み取れた事実(候補者の言葉をそのまま引用)
- 評価コメント(100字以内)
- 懸念点があれば(任意)
注意:最終的な合否判断はしないこと。事実と観察のみを記載する。採用プロンプト4:ポジション別面接質問リスト
以下のポジションの面接で使える質問リストを作成してください。
【ポジション】[職種名]
【必須スキル・経験】[リスト]
【求める行動特性】[例:自走力・チームリーダーシップ・顧客志向 など]
【NG項目】[聞いてはいけないこと / 確認が不要な項目]
出力:
1. アイスブレイク(3問)
2. 過去の経験・実績を聞く質問(10問、STARメソッド形式で掘り下げやすいもの)
3. 問題解決・思考プロセスを見る質問(5問)
4. 志望動機・カルチャーフィット確認(5問)
5. 候補者からの逆質問を促すフレーズ(3問)
各質問に「この質問で何を確認したいか」の意図を1行で添えてください。採用プロンプト5:不合格通知メールの作成
以下の情報を基に、不合格通知メールを作成してください。
【候補者名】[名前](敬称は自動付与)
【選考ステップ】[書類/一次面接/最終面接]
【お見送りの理由(社内向け)】[正直な理由。メールには婉曲表現を使う]
【良かった点】[候補者の良かった点(1〜2個)]
【会社名・担当者名】[会社・名前]
条件:
- 候補者の今後のキャリアを尊重するトーン
- 理由は「弊社の現在のニーズとの合致度」という表現に留める
- 候補者が良かったと思える点を1文入れる
- 300字以内で完結させる
- 将来の応募機会を否定しない(ただし「ぜひまた」と誤解させない表現で)ATS連携:ChatGPTと採用管理システムをつなぐ3つのアプローチ
「ATS(Applicant Tracking System)は使っているけど、ChatGPTとどうつなぐかわからない」という声が採用担当者から増えています。2026年6月時点での現実的な3アプローチを紹介します。
アプローチ1:コピペ運用(最も簡単・すぐ始められる)
ATSの候補者情報をコピーしてChatGPTに貼り付け、スカウト文・評価コメントを生成して貼り直す。ツール連携なし、明日から始められます。デメリットは手作業が残ること。
アプローチ2:Zapier/Make経由の半自動連携
Zapierを使い「ATSに新規応募 → ChatGPT APIで評価サマリ生成 → ATSのコメント欄に自動入力」を構築します。ノーコードツールの知識があれば2〜3時間で構築可能。月額コストはZapier $20前後+API利用料。
アプローチ3:ChatGPT Workspace AgentsとATSの連携(中級〜上級)
ATSがSlack・GmailのWebhookに対応している場合、Workspace Agentsを経由して「応募通知 → スクリーニング補助 → 担当者へのSlack通知」まで自律実行できます。現状は主要ATS(Workday・Greenhouse・SmartHR等)の連携対応が拡充中。詳細は各ATSのOpenAI連携ドキュメントを確認してください。
採用AI活用の注意事項(法的・倫理的配慮)
採用業務でAIを使う場合、特に以下の点を社内ルールとして明文化することを推奨します。
- 個人情報の入力ルール:候補者の氏名・連絡先・生年月日などの個人情報はChatGPT(プロンプト)に直接入力しない。名前は「Aさん」「候補者」に置換する
- 合否判断はAIに委ねない:ChatGPTの出力はあくまで「補助情報」。最終的な選考判断は必ず人間が行う。「AIが落とした」はNG
- バイアスの確認:面接評価コメントの生成後、年齢・性別・出身地などの情報が評価に影響していないかを確認する
- 応募者への開示:採用選考にAIを活用していることを採用ページや面接前に明示することを検討する(2026年時点では法的義務はないが、候補者の信頼確保の観点から有効)
事例区分: 公開事例参照
採用担当者の負担軽減という観点では、船井総合研究所の事例(公開資料参照)でもChatGPTによる採用業務自動化で「7つの業務を1秒で完了」という効果が報告されています。一方で、採用の質を保つためには「AI生成の下書きを人が読んで判断する」プロセスの設計が不可欠です。AIは「量をこなす部分」を担い、採用担当者は「判断と関係構築」に集中するという役割分担が、2026年の採用AI活用の最適解と考えています。
関連リソース(外部メディア)
AIで自身のキャリア戦略を組み立てたい経営者・コンサルの方には、エグゼクティブ向けキャリア専門メディアもおすすめです
OpenAI Codex の社内導入、Uravationが伴走支援します
Codex CLI のチーム展開、AGENTS.md 設計、エンタープライズプラン選定まで100社以上の知見から最適解をご提案。
- 100社以上の企業支援実績
- 初回30分無料・即日返信
- 導入後3ヶ月の伴走付き
お問い合わせフォームから24時間以内にUravation担当者がご返信します。











