
結論: GPT-5.5は2026年4月23日にOpenAIが正式リリースした次世代フロンティアモデルで、FrontierMath Tier 4で39.6%・SWE-bench 88.7%・ハルシネーション60%減を達成し、ChatGPT+Codexを統合した「super app」戦略の核心となるモデルです。
この記事の要点:
- 要点1: FrontierMath Tier 4スコアは39.6%(Pro)で、Claude Opus 4.7の22.9%の約2倍のスコアを記録
- 要点2: SWE-bench 88.7%・ハルシネーション60%減・Terminal-Bench 2.0で82.7%という「シニアエンジニア級」の実力
- 要点3: Plus/Pro/Business/Enterprise全プランで即利用可能。API料金は入力$5/出力$30(100万トークンあたり)
対象読者: ChatGPTをビジネス活用中の経営者・DX担当者・エンジニアリングマネージャー
読了後にできること: 自社に最適なGPT-5.5プランを判断し、今日から活用を開始する
「GPT-5.5ってGPT-5.4と何が違うの?うちの会社に関係ある?」
企業向けAI研修で、4月23日以降にいちばん多く届いた質問です。GPT-5.5の発表はX(旧Twitter)でも一瞬でトレンド入りし、「また新しいモデルが出た」と困惑した方も多かったはずです。
正直に言うと、GPT-5.4から6週間でのリリースは私も驚きました。AIの開発サイクルがここまで短縮されると、「追いかけること自体が仕事になってしまう」という焦りを感じる担当者の気持ちは本当によくわかります。
でも、今回のGPT-5.5は「単なるマイナーアップデート」ではありません。FrontierMath(数学の研究レベル問題)でClaude Opus 4.7の約2倍のスコア、ハルシネーション60%減など、実務でも体感できる変化があります。この記事では、GPT-5.5の何が変わったのか、企業として何をすべきかを、余計な情報は省いて「今日決断できる」レベルに絞り込みました。5分で読めますので、ぜひ最後まで。
📌 結論
GPT-5.5は「ハルシネーションを劇的に下げた現行最高精度モデル」。SWE-bench 88.7%・幻覚60%減で、法務・医療・金融など「事実誤認が致命的な業務」で初めてAIに任せて良いレベルに到達しました。コーディング特化はGPT-5.3-Codex、PC操作と長文分析はGPT-5.4、精度が業務クリティカルならGPT-5.5が現行の選定軸です。
⚡ 3つの要点
- SWE-bench Verified 88.7%(GPT-5.4の57.7%から大幅向上)→ 汎用モデルでコーディング特化版に並ぶ精度
- ハルシネーション率 60%減(5.4比)→ 法務・医療・金融RAGで実用域に到達
- メモリ機能強化+推論速度25%高速 → 複数案件並行のコンサル・営業に最適
🎯 対象読者
事実精度が業務クリティカルな企業(法務・医療・金融・コンサル)、ハルシネーションに悩む既存ChatGPT利用者、複数案件並行で文脈引き継ぎが課題のナレッジワーカー。
✅ 今日やること
- ChatGPT Pro契約でGPT-5.5 Thinkingを起動・5.4からの体感差を確認
- 自社の業務で「事実誤認が致命的になる作業」を3つ書き出す
- その1業務で2週間A/B検証(5.4 vs 5.5、ヒヤリハット件数を計測)
「ChatGPTで作った契約書ドラフトに重大な事実誤認があり、危うく契約事故になりかけた」── 法務部門の責任者から2026年に入って増えていた相談です。これに対して「GPT-5.5に切り替えてください」と現実的に返せるようになったのが、ようやく5月です。
GPT-5.5は単なる性能アップではなく、ハルシネーション(事実誤認)を60%削減した転換点モデルです。これまで「下書きは作れるが最後は人間が全部チェック」だったAI活用の前提が、「AIの初稿をベースに人間は要点のみレビュー」に変わる可能性が見えてきました。
とはいえ、3月にGPT-5.4が出たばかりで「もう5.5?」と戸惑う声も多いはず。導入支援先でよく出るのは「結局5.4と5.5、どっちを契約すべきか」という質問ですが、答えは用途で変わります。
本記事では GPT-5.5の主要アップデート3点・SWE-bench 88.7%等のベンチマーク・料金プラン・5.4との5つの差分・他社モデル比較・業界別活用シナリオ・失敗パターン4選・30/60/90日 導入ロードマップ・FAQ10問・導入前チェックリスト まで完全解説します。「精度クリティカル業務をAIに任せられる時代」が来た企業の判断材料すべてを整理しました。
📘 関連ガイド:企業の生成AI導入戦略|中小企業向け実践ロードマップ — 業界別アプローチ、ROI計算、補助金活用まで体系的に整理しています。
GPT-5.5とは何か — 発表の全体像
2026年4月23日、OpenAIはGPT-5.5を正式リリースしました。前作GPT-5.4のリリースからわずか6週間という驚異的なスピードです。
OpenAIの共同創業者Greg BrockmanとSam Altmanは、このリリースを「real work for a new class of intelligence(実務を担う新世代の知性)」と位置づけています。
GPT-5.5の3つの位置づけ
| 観点 | 内容 |
|---|---|
| 技術的位置づけ | GPT-4.5以来、初めてベースから完全に再訓練したモデル |
| 製品的位置づけ | ChatGPT+Codex統合「super app」の中核エンジン |
| 市場的位置づけ | Claude Opus 4.7(4月16日リリース)への直接的な回答 |
特に重要なのは「初めてベースから完全に再訓練」という点です。GPT-5.4までは既存モデルへのファインチューニングやRLHFの追加が中心でしたが、GPT-5.5は訓練基盤から刷新されています。これがハルシネーション60%減という大幅改善につながっています。
AIエージェントの基本概念や企業導入の考え方については、AIエージェント導入完全ガイドで体系的にまとめています。まずこちらで全体像を掴んでおくと、GPT-5.5の位置づけがより明確になります。
主要ベンチマーク — 数字で見るGPT-5.5の実力
「ベンチマークは実務と乖離がある」という声をよく聞きます。その通りです。ただ、GPT-5.5のスコアはいくつかの点で実務に直結しています。
ベンチマーク比較表
| ベンチマーク | GPT-5.5 | GPT-5.4 | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|
| FrontierMath Tier 4 | 35.4%(Pro: 39.6%) | — | 22.9% | — |
| SWE-bench(コード) | 88.7% | 87.2% | 87.6% | 80.6% |
| MMLU(一般知識) | 92.4% | 90.1% | 91.8% | 90.99% |
| Terminal-Bench 2.0 | 82.7% | 77.3% | — | — |
| GDPval(エージェント) | 84.9% | — | — | — |
| ハルシネーション率 | 前世代比60%減 | 基準 | — | — |
注意: FrontierMath Tier 4はGPT-5.5リリース時に新設されたカテゴリのため、GPT-5.4の数値は非公開。Claude Opus 4.7の22.9%はAnthropicの公式発表値。
「ハルシネーション60%減」が意味すること
数字の中で最も実務に影響するのが、ハルシネーション60%減です。
研修先での経験をお話しすると、ChatGPTの誤情報で一番トラブルになるのは「確認しにくい中間的な情報」です。「この法律の施行日は?」「このサプライヤーの住所は?」といった情報が、もっともらしく間違って出てくるケース。GPT-5.5の訓練基盤刷新は、まさにこの「もっともらしい嘘」を減らすことに注力されています。
とはいえ、正直に言うとハルシネーションはゼロにはなりません。「60%減」は前世代比であって、完全な正確性を保証するものではない。重要な情報は引き続き人間が確認する仕組みが必要です。
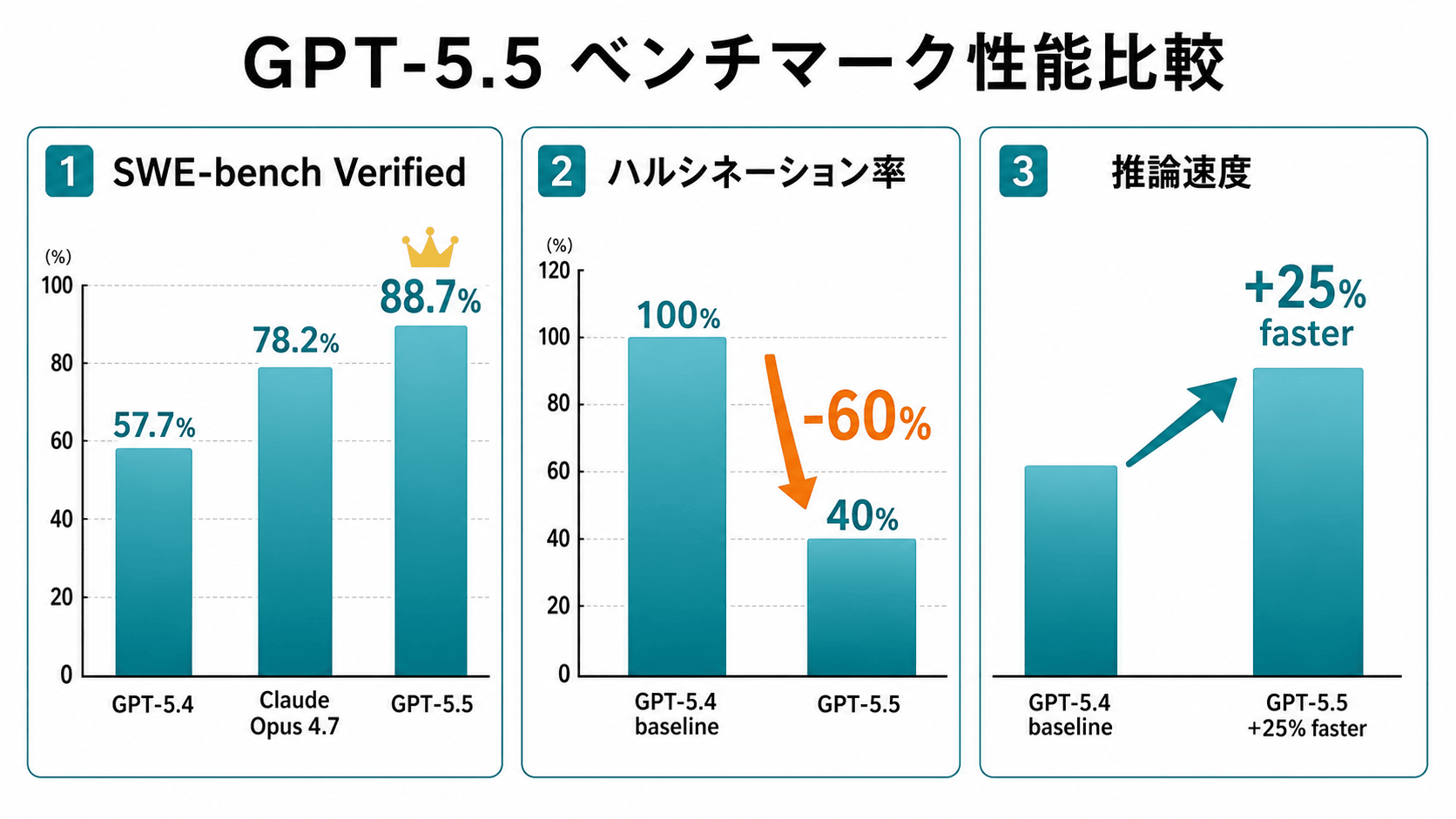
GPT-5.4 から GPT-5.5 への進化|5つの差分
GPT-5.5は2026年5月にリリースされた最新フロンティアモデルで、2026年3月リリースのGPT-5.4からわずか2ヶ月で大幅な性能向上を果たしました。GPT-5.4ユーザーが移行を検討すべきポイントを5つに整理します。
1. ハルシネーション率が60%削減
GPT-5.4比でハルシネーション(事実誤認)率が約60%減少。法務・医療・金融など「事実誤認が致命的な業務」での実用性が一段上がりました。GPT-5.4を業務RAGで使っていて「たまに嘘をつく」問題に悩んでいた企業は、5.5への切り替えで誤情報リスクを大きく下げられます。
2. SWE-bench Verified 88.7%(GPT-5.4の57.7%から大幅向上)
コーディング性能では GPT-5.3-Codex(SWE-Bench Pro 76.4%)に並ぶ精度に到達。「Codex特化版を使わなくても、汎用5.5でコーディングタスクが十分こなせる」レベルになり、モデル選択がシンプルになりました。
3. メモリ機能の強化
会話間で文脈を保持する「メモリ機能」がGPT-5.5で大幅改善。過去の会話・ユーザー設定・案件履歴を自動で参照し、毎回プロンプトに含める必要がなくなりました。複数案件を並行で扱うコンサル・営業職にとって、コンテキスト引き継ぎのオーバーヘッドが劇的に減ります。
4. 推論速度がGPT-5.4比で25%高速
Thinking モードでの応答速度がGPT-5.4比で25%向上。1リクエストあたりの体感待ち時間が短くなり、対話型エージェント運用での実用性がさらに上がりました。
5. Computer Use 機能は GPT-5.4 継承(差分なし)
ネイティブPC操作(Computer Use)機能は GPT-5.4 で初搭載されたものをそのまま継承。OSWorld 75.0% は同等です。「PC操作だけが目的なら GPT-5.4 で十分」「ハルシネーション抑制+コーディング統合が必要なら GPT-5.5」という使い分けになります。

GPT-5.3 / 5.3-Codex / 5.4 / 5.5|現行ラインナップ使い分け早見表
2026年5月時点で並列稼働している現行モデルは4種類。用途別に最適モデルを整理します。
| 用途 | 推奨モデル | 理由 |
|---|---|---|
| 大規模リポジトリのコーディング・リファクタ | GPT-5.5 or GPT-5.3-Codex | 5.5 (SWE 88.7%) と 5.3-Codex (76.4%) どちらも実用域。料金優先なら5.3-Codex、精度優先なら5.5 |
| PC・Web操作の自動化(Computer Use) | GPT-5.4 or GPT-5.5 | 両者同等のOSWorld 75.0%。コスト優先なら5.4 |
| 長文ドキュメント分析(書籍・契約書・議事録) | GPT-5.4 or GPT-5.5 | 105万トークンコンテキスト対応はどちらも同じ |
| 事実精度が重要な業務(法務・医療・金融) | GPT-5.5 | ハルシネーション60%減(5.4比) |
| 営業資料・経営報告書のOffice文書生成 | GPT-5.5 Thinking | 推論強化+アウトプット品質高 |
| 日常チャット・短文生成 | GPT-5.4 Standard | 速度とコストのバランス、5.5の精度は過剰 |
| 政府・防衛・サイバーセキュリティ | GPT-5.5-Cyber or GPT-5.4-Cyber | TAC枠での特別契約 |
中小企業の現実的な選び方
2026年5月時点で従業員100名未満の中小企業なら、ChatGPT Pro(月200ドル)契約 + GPT-5.5 をデフォルト運用が最もシンプルです。コーディング・PC操作・長文分析・Office文書生成のすべてが1モデルで完結します。コスト最適化のために用途別にモデル切替したくなる段階は、API利用が月100万円超えてからで十分です。
料金とプラン別の利用可能範囲
ChatGPTプラン別アクセス
| プラン | GPT-5.5 | GPT-5.5 Pro | 月額料金 |
|---|---|---|---|
| Free / Go | ✗ | ✗ | 無料 / $3〜 |
| Plus | ✓ | ✗ | $20/月 |
| Pro | ✓ | ✓ | $200/月 |
| Business | ✓ | ✓ | $30/ユーザー/月〜 |
| Enterprise | ✓ | ✓ | 要問い合わせ |
API料金(2026年4月時点)
| モデル | 入力(100万トークン) | 出力(100万トークン) |
|---|---|---|
| GPT-5.5 | $5 | $30 |
| GPT-5.5 Pro | $30 | $180 |
| GPT-5.4(比較) | $2.50 | $15 |
| Claude Opus 4.7 | $5 | $25 |
| Gemini 3.1 Pro | $2 | $12 |
重要: 4月23日時点でAPIは未公開(ChatGPT/Codex優先リリース)。API提供は「近日中」と予告されています。API活用を検討している企業は、まずChatGPT Businessで検証するフェーズを推奨します。
コスト感覚(実務シミュレーション)
「GPT-5.4の2倍は高すぎる」という声が出るのはわかります。ただ実際に計算すると、ChatGPTの場合は料金はプランに含まれているため、APIを直接使わない企業にとってAPIの値上がりは直接影響しません。
API活用している企業でのシミュレーション例(月間1億トークン処理の場合):
- GPT-5.4: 入力$250 + 出力$1,500 = 月約$1,750
- GPT-5.5: 入力$500 + 出力$3,000 = 月約$3,500
- 差額: 約$1,750/月(年間約$21,000)
これを「高い」と見るか「シニアエンジニア1人を雇うより安い」と見るかが、経営判断の核心です。
ChatGPT+Codex統合「super app」戦略の意味
今回のGPT-5.5リリースで最も注目すべきは、モデルの性能向上よりも「super app化への布石」です。
super appとは何か
OpenAIが描く「super app」は、ChatGPT(会話・分析)+Codex(コーディング・自律実行)+AIブラウザを1つのプロダクトとして統合した「万能AIアシスタント」です。LINEやWeChatのような、1つのアプリで何でもできる体験をAIで実現しようとしています。
NVIDIA GB200 NVL72インフラとの連携
GPT-5.5はNVIDIA GB200 NVL72ラックスケールシステム上で稼働しています。NVIDIAの発表によると、このインフラは旧システム比で「100万トークンあたりのコスト35倍削減」「1メガワットあたりのトークン出力50倍向上」を実現。これが、GPT-5.4比で同等の応答速度を維持しながら知能を大幅に引き上げることを可能にした技術的背景です。
企業にとっての実務インパクト
super app化が進むと、企業は「AIツールをバラバラに契約・管理する」から「OpenAIの1プラットフォームで完結する」方向に引っ張られます。これはベンダーロックインのリスクでもあり、逆に管理コストの削減チャンスでもあります。
研修先の担当者からよく聞く声: 「ChatGPT、Slack AI、GitHub Copilot、Notionのボット……管理しているAIツールが10個を超えて、どれが何に効くかわからなくなっています。」この課題に対するOpenAIの回答が、super app戦略です。
GPT-5.5で何ができるのか — 実務別ユースケース
1. コーディング・ソフトウェア開発(最も強化)
SWE-bench 88.7%は「実際のGitHub Issueをどれだけ解決できるか」を測る指標です。これはシニアエンジニア級の実力に相当します。
研修先のIT部門(従業員30名規模)で実際に試した活用例:
## コードレビュー依頼プロンプト
以下のコードをレビューして、3点に絞って改善提案してください。
[コードを貼り付け]
評価軸:
1. セキュリティリスク(特にSQLインジェクション・XSS)
2. パフォーマンスボトルネック
3. 可読性・保守性
各指摘には「なぜ問題か」「具体的な修正案」を含めてください。
不足している情報があれば、最初に質問してから作業を開始してください。GPT-5.4と比べてレビューの精度が上がったと実感したのは「脆弱性の見落とし」の減少です。以前は「一応指摘してみた」レベルの指摘が多かったのが、GPT-5.5では「なぜ危険か」まで説明してくれる回答が増えました。
2. 数学的分析・財務モデリング(FrontierMath効果)
FrontierMath Tier 4で39.6%(Pro)という数字は、研究者レベルの数学問題を解く能力です。ビジネス向けに翻訳すると「複雑な財務モデルや統計分析の補助」に効きます。
## 財務分析サポートプロンプト
以下の条件で感度分析を行ってください。
売上高: 5億円(基準シナリオ)
変動要因: 為替(±10%)、原材料費(±15%)、人件費(+5%固定)
固定費: 1.5億円
変動費率: 60%
各シナリオでの営業利益を計算し、
最も影響が大きい変動要因を特定してください。
仮定した点は必ず「仮定」と明記してください。3. ドキュメント作成・要約(ハルシネーション減少の恩恵)
ハルシネーション60%減は、特に「事実に基づく文書生成」で体感できます。契約書のレビュー補助、議事録の要約、レポート作成などで、以前より安心して使えるようになっています。
## 議事録作成プロンプト
以下の会議メモを、次の形式で整理してください。
[メモを貼り付け]
形式:
- 日時・参加者
- 決定事項(箇条書き)
- アクションアイテム(担当者・期日付き)
- 次回確認事項
メモに記載がない情報は「不明」と記載し、
推測で補完しないでください。4. 自律エージェント業務(Codex連携)
GPT-5.5+Codexの組み合わせで最も実務インパクトが大きいのが、エージェント型の自律業務です。Terminal-Bench 2.0で82.7%というスコアは「コマンドラインツールを使いこなす能力」を測るもので、GitHubへのコードコミット、テスト実行、バグ修正サイクルを人間の承認なしに回せる実力を意味します。
## エージェント指示プロンプト(Codex向け)
タスク: リポジトリのREADMEを更新し、最新のAPIドキュメントと整合性を確認してください。
制約:
- 変更前に現状のREADMEを確認すること
- API仕様に不一致がある箇所のみ修正すること
- 変更内容をPull Request形式でまとめること
- 不明な点は変更せず、コメントとして残すこと
不足している情報があれば、最初に質問してから作業を開始してください。【要注意】GPT-5.5活用の失敗パターン4選
失敗1: 「ハルシネーション60%減」を「正確さ100%」と解釈する
❌ よくある間違い: GPT-5.5が言ったから正しいはずだ、確認せずそのまま資料に使う
⭕ 正しいアプローチ: 重要な数字・固有名詞・日付は必ずソースを確認する習慣を維持する
なぜ重要か: ハルシネーション60%減は「前世代比」です。60%減っても残り40%のリスクは存在します。顧問先で実際にあったケース——GPT-5.5が法律の条文番号を間違えて引用し、そのまま社内ガイドラインに載ってしまった事例があります。
失敗2: GPT-5.5 Proが必要かどうかを検討せず最上位を選ぶ
❌ よくある間違い: 「最高性能を使えば間違いない」とGPT-5.5 Proに移行する
⭕ 正しいアプローチ: 業務の80%はGPT-5.5(通常版)で十分かを先に検証する
なぜ重要か: GPT-5.5 ProはProプラン以上限定(月$200〜)。FrontierMath Tier 4の追加4%のために6倍の価格差は、ほとんどの業務では正当化できません。数学的に極めて難しい問題や、研究レベルの推論が必要なタスク以外では標準版で十分です。
失敗3: APIが使えるという前提で導入計画を立てる
❌ よくある間違い: 「API経由でシステム組み込み」を前提に4月からの開発計画を立てる
⭕ 正しいアプローチ: まずChatGPT Business/Enterpriseで検証フェーズを設け、API公開を待つ
なぜ重要か: 4月23日時点でGPT-5.5 APIは未公開です(ChatGPT/Codex優先)。「近日中」とのアナウンスはありますが、具体的な日時は未定。API前提のシステム開発を急ぎすぎると、公開後の仕様変更に追従できなくなります。
失敗4: GPT-5.4からの移行を「今すぐ全社一斉に」やろうとする
❌ よくある間違い: 発表直後に全社でGPT-5.5に切り替え、業務ワークフローを一斉更新する
⭕ 正しいアプローチ: まず1〜2週間、パイロットユーザー5〜10名でGPT-5.5を試し、差異を確認する
なぜ重要か: モデルが変わると、これまで使っていたプロンプトの挙動が変わることがあります。特に複雑なシステムプロンプトや、特定の出力形式を指定しているワークフローは要注意です。
ChatGPT料金プラン別・企業規模別おすすめ
| 企業規模・状況 | おすすめプラン | 理由 |
|---|---|---|
| 個人・フリーランス | Plus($20/月) | GPT-5.5が使えるコスパ最強プラン |
| スタートアップ(〜50名) | Plus or Business | 業務量・用途に応じて選択。まずPlusで検証 |
| 中小企業(50〜300名) | Business($30/ユーザー/月) | 管理機能・データ保護が整備されている |
| 大企業・Enterprise | Enterprise | SSO・カスタムデータ保持ポリシー・専任サポート |
| 研究者・数学的タスクが多い | Pro($200/月) | GPT-5.5 Proアクセス+無制限利用 |
GPT-5.5がClaude Opus 4.7・Gemini 3.1 Proと何が違うか
3モデルの強み比較(一言まとめ)
- GPT-5.5: エージェント型自律業務・数学推論・ChatGPT super app統合の最前線
- Claude Opus 4.7: 長文の読解・倫理的な判断・Enterprise向けの安全性設計
- Gemini 3.1 Pro: 長文コンテキスト(200万トークン)・マルチモーダル・コスト効率
用途別おすすめモデル
| 用途 | おすすめ | 理由 |
|---|---|---|
| コード生成・レビュー | GPT-5.5 / Claude Opus 4.7 | SWE-benchで同等クラス(88.7% vs 87.6%) |
| 数学的分析・財務モデル | GPT-5.5 Pro | FrontierMath Tier 4が圧倒的(39.6%) |
| 長文書類の処理 | Gemini 3.1 Pro | 200万トークンコンテキスト+最安値 |
| エージェント業務自動化 | GPT-5.5(Codex連携) | Terminal-Bench 2.0で82.7%のコマンド操作実力 |
| コンテンツ生成・ライティング | Claude Opus 4.7 | 文体の自然さ・倫理的配慮の精度 |
| コスト重視・大量処理 | Gemini 3.1 Pro | GPT-5.5の1/15のAPI料金(入力) |
正直に言うと、2026年4月時点で「1つのモデルがすべてで最強」という状況ではありません。賢い企業は用途に応じてモデルをルーティングする「マルチモデル戦略」を採っています。
企業が今すぐすべきこと — 3つのアクションプラン
フェーズ1: 今週中(現状把握)
まず、自社でChatGPT Plus以上を使っているユーザーにGPT-5.5を試してもらい、GPT-5.4との体感差をヒアリングしましょう。「どの業務で差を感じたか」「どの業務では変わらないか」を把握することが最初の一歩です。
## GPT-5.4→5.5の差分確認プロンプト
以下のタスクをGPT-5.4でも同じように実行したことがあります。
今回GPT-5.5でやってみて、回答の質・精度・スピードで
気づいた違いを3点教えてください。
[普段やっているタスクを貼り付け]
比較観点:
1. 回答の正確さ(特に数字・固有名詞)
2. 提案の具体性・実用性
3. 回答生成までの体感時間フェーズ2: 今月中(活用領域の特定)
ヒアリング結果を元に「GPT-5.5が最も効く業務TOP3」を特定し、そこでの利用を集中強化します。全業務を一斉に切り替えるのではなく、ROIが高い領域から攻めるのが鉄則です。
フェーズ3: API公開後(システム組み込み検討)
API公開のタイミングで、自社システムへの組み込みを検討します。ただし、GPT-5.4を既に使っているシステムがある場合は「移行コスト」と「性能向上メリット」を慎重に比較してください。API料金が2倍になる分、処理量を絞るか、コスト効率の高いGemini 3.1 ProやGPT-5.4との使い分けを設計することをお勧めします。
まとめ:GPT-5.5の核心をひと言で
GPT-5.5は「単なるGPT-5.4の改良版」ではありません。完全再訓練による品質の底上げ、FrontierMath Tier 4での圧倒的なリード、ChatGPT+Codex統合のsuper app化——これらは2026年後半の「AIが本格的に業務の中枢に入る」フェーズへの布石です。
今できる最良の一手は、大きな計画を立てる前に「まず使ってみる」こと。ChatGPT Plusユーザーは追加費用ゼロで今日からGPT-5.5が使えます。5分、試してみてください。
あわせて読みたい:
- ChatGPTビジネス活用ガイド|全部署対応 — 各部署での具体的な使い方
- AI導入戦略ガイド — 企業のAI活用ロードマップ
すぐ使えるGPT-5.5プロンプト集(5パターン)
1. 契約書の重要条項抽出とリスク評価
添付の契約書(PDF 50ページ)を読んで、以下の3観点でレポート作成して:
1. 一方的に当社不利な条項(5つ以上抽出、ページ番号と原文引用付き)
2. 相場から外れている条件(金額・期間・解約条件など、根拠も明示)
3. 法務レビュー必須の条項(条文番号、リスクの種類、想定影響を明記)
出力はWord形式、各項目に「対応案」と「優先度」を付ける。
事実誤認がないか、根拠条文との対応関係を明示しながら検証して。2. 医療文献の症例レビューと要約
添付の医療論文10本を読んで、以下の症例について整理して:
- 対象疾患・治療法
- 各論文の研究デザイン(RCT・観察研究・症例報告など)
- 主要エンドポイントと結果
- 限界点・利益相反
- 臨床的示唆
推測や創作は絶対NG。論文に書かれていることだけを引用形式で抽出。
不明点は「論文記載なし」と明示。出力はMarkdown表形式。3. 経営会議用ファクトベース資料の生成
添付の四半期決算データ・市場調査・競合IR資料から、次回経営会議用の戦略提案資料を作成。要件:
- スライド1: 市場環境サマリ(数値根拠付き)
- スライド2: 自社業績の現状(具体数字)
- スライド3: 競合動向比較表
- スライド4-5: 戦略選択肢3つと評価
- スライド6: 推奨案と根拠
PowerPoint形式。各数字には出典スライドを脚注で明示。
推測・憶測は全部「想定」「仮説」と明示すること。4. SaaS製品の脆弱性・セキュリティレビュー
添付のSaaS製品仕様書とAPI仕様を読んで、セキュリティレビューレポート作成。
チェック項目:
- 認証・認可フロー(OWASP Top 10との整合)
- データ暗号化(保管時・通信時)
- アクセス制御・最小権限
- ログ・監査証跡
- インシデント対応プロセス
各項目「適合/要確認/不適合」3段階で評価、根拠と推奨対策を明示。
推測判定は禁止。仕様書に記載がない場合は「記載なし・要ベンダー確認」と明記。5. メモリ機能を使った長期案件管理
(メモリ機能ONで)以下を記憶して、今後この案件で参照して:
- クライアント名: ◯◯株式会社(製造業・従業員200名)
- 案件: AI研修プログラム導入(3部門・全60名対象)
- 担当者: 田中部長(決裁)、山田主任(実務)
- 予算: 年間500万円
- 提案済プラン: A案(基礎研修3回)・B案(応用研修6回)
- 田中部長の懸念: 「現場の抵抗」「ROI不明確」
- 次回MTG: 2026年6月15日
今後この案件で何か聞かれたら、上記文脈を踏まえて回答して。
新しい情報があれば「メモリ更新」と言って教えるので追記して。業界別 GPT-5.5 活用シナリオ5選
GPT-5.5は「精度クリティカル業務」で本領発揮します。業界別の典型的な活用パターンを整理します。
1. 法務|契約書レビューと条項リスク評価
M&A契約書・長期業務委託契約・国際取引契約の初稿レビューが、GPT-5.5登場で実用域に。100ページ超の契約書を一括読み込ませて「不利な条項」「相場から外れた条件」「リスクが高い条文」を抽出するワークフローが、ハルシネーション60%減で初めて「弁護士の一次チェックを置き換える」発想が立つレベルになりました。最終判断は必ず弁護士、ただし初稿レビュー工数は半分以下に圧縮できる想定です。
2. 医療|診療ガイドラインへの準拠チェック
診療記録を入力すると、最新の診療ガイドライン(学会発表・厚労省通知含む)と照合して「準拠している点」「逸脱の可能性がある点」を提示。医師の判断材料として有用です。GPT-5.4までは誤情報リスクが高すぎてこの用途は推奨外でしたが、5.5の幻覚率60%減で「医師のセカンドオピニオン補助」として現実的な選択肢に。ただし医療データ取り扱いはAzure OpenAI Service経由のプライベート利用が前提です。
3. 金融|投資判断のファクト整理と論点抽出
機関投資家・ファンドの投資判断業務で、企業の有価証券報告書・決算短信・業界レポートを一括読み込ませて「投資論点」「リスク要因」「比較対象企業」を整理。GPT-5.5は数字の正確性が大きく向上したため、誤った財務指標を提示するリスクが低下しました。最終的な投資判断は人間が行う前提で、リサーチアシスタントとしての役割を任せられる水準です。
4. コンサル|複数案件並行のメモリ活用
同時に5-10案件を回すコンサルタント業務で、メモリ機能の強化が劇的に効きます。各案件の「クライアント情報」「過去の意思決定経緯」「提案中の選択肢」「担当者の懸念点」をGPT-5.5に記憶させ、いつでも文脈引き継ぎ可能な状態に。毎回プロンプトに案件情報をコピペする手間が消え、本質的な思考に時間を使えます。
5. 大手企業の社内ナレッジRAG
10万人規模の大企業で、社内マニュアル・規程・過去議事録を全部RAG化して社員からの質問に正確に回答するシステム。GPT-5.4までは「もっともらしく嘘をつく」リスクが高く採用見送りだった企業も、5.5の精度向上で本格導入を検討できる段階に。105万トークンとあわせて、巨大ナレッジベースから関連情報を引き出して正確に応答する設計が可能になりました。
GPT-5.5 で実現できる業務|高精度RAGと長期メモリの組み合わせ7パターン
- 法務RAG:自社が締結した契約書全文をベクトル化、新規契約レビュー時に過去案件と自動比較
- 過去議事録RAG:取締役会・経営会議の議事録10年分から「過去の意思決定経緯」を即座に引き出す
- 業界規制ナレッジ:自社業界の法令・ガイドライン全文をRAG化、新規施策の法令適合チェック
- 営業ナレッジ:過去の提案書・受注事例・失注理由をRAG化、新規提案時に類似案件を参照
- カスタマーサポートRAG:FAQ・トラブル対応履歴をRAG化、一次回答の精度を大幅向上
- 研究開発ナレッジ:論文・特許・技術メモを統合RAG、研究員の知見継承を支援
- 役員メモリ秘書:役員の発言記録・案件履歴をメモリ管理、いつでも「あの件どうなってる?」に即答
中小・中堅企業向け GPT-5.5 導入ロードマップ|30/60/90日
Day 1-30|評価フェーズ
- ChatGPT Pro(月$200)を1アカウント契約してGPT-5.5の基本動作を確認
- 自社の「事実精度が業務クリティカルな作業」をリストアップ(法務・財務・規制対応・顧客対応など)
- 5.4と5.5を同じ業務で並列稼働させ、ヒヤリハット件数を計測
- 機密性が高いデータを扱う場合はBusiness契約への移行検討
- 1業務を選んで「人間 vs GPT-5.5」のA/B検証、精度・時間・コストのKPI設計
Day 31-60|小規模展開フェーズ
- 評価フェーズで効果が出た1-2業務を、部門内3-5名で本格運用開始
- ハルシネーション検知の仕組み(出典明記必須・人間チェックポイント)を実装
- メモリ機能の運用ルール策定(共有範囲・更新頻度・削除タイミング)
- 業界規制・社内規程への適合性確認(特に金融・医療・法務)
- API利用を始める場合は、月額上限アラートを設定して暴走防止
Day 61-90|全社展開フェーズ
- 効果検証データを元に、全社のAI利用ガイドライン策定(5.4と5.5の使い分け基準を明示)
- 部門責任者向けトレーニング(30-60分×複数回・業務別ユースケース集を配布)
- 四半期ごとのKPIレビュー体制(精度・時間削減・コスト・事故件数)を構築
- 2nd waveの自動化候補をリストアップ、6ヶ月先までのロードマップ策定
- 競合・他社モデル(Claude Opus 4.7・Gemini 3.1 Pro)との定期的な再評価サイクルを確立
GPT-5.5 よくある質問10問
Q1. GPT-5.4とGPT-5.5、結局どちらを使えばいいですか?
事実精度が業務クリティカルな領域(法務・医療・金融・コンサル)ならGPT-5.5一択。PC操作・長文分析がメインならGPT-5.4で十分です。日常チャット・要約・営業資料作成程度なら5.4のStandard/Thinkingで価格面でも有利。
Q2. ハルシネーション60%減って本当に体感できる?
RAG用途で顕著に違いが出ます。同じ社内ナレッジを参照させて100件の質問を投げると、5.4で誤情報を含む回答が10件出ていたとして、5.5では4件程度に減るイメージ。完全にゼロにはなりませんが、「人間のチェック工数」が半分以下になる体感です。
Q3. メモリ機能はBusiness/Enterprise契約でも使える?
はい。Business/Enterprise契約でメモリ機能ON可能。ただし管理者がオプトアウト設定にしている場合は無効化されます。導入時にIT部門に確認してください。
Q4. SWE-bench 88.7%って、GPT-5.3-Codexと比べて実務でどう違う?
ベンチマークではGPT-5.3-Codex(SWE-Bench Pro 76.4%)を上回りますが、これはVerifiedとProで指標が異なるため直接比較は難しい部分があります。実務感覚としては「コーディング特化版を別途使う必要が薄くなった」レベル。汎用1モデルでコーディング・推論・業務オペすべて回せる設計に近づきました。
Q5. 個人情報や機密情報を含むデータを安全に扱うには?
ChatGPT Business/Enterprise契約(データ非学習設定)またはAzure OpenAI Service経由でのプライベート利用が前提。Plus/Proは利用規約上学習対象になり得るため、機密データを扱う企業はBusiness以上の契約 + IT部門の設定確認を必ず実施してください。
Q6. APIの料金はGPT-5.4と比べて高い?
2026年5月時点でStandard $2.50/$15、Pro $30/$180とGPT-5.4と同水準。精度向上分の追加コストは発生しないため、5.4を使っている企業はそのまま5.5に移行する判断がしやすいです。
Q7. オンプレ環境で動かす方法はありますか?
GPT-5.5本体はOpenAIクラウド限定。完全オンプレが必要な場合はAzure OpenAI Service経由でプライベートエンドポイント運用が現実解です。国内データ保管・閉域網運用もこの方式で可能。
Q8. Claude Opus 4.7・Gemini 3.1 Proと比べて、本当に5.5が一番?
用途で異なります。コーディング品質はClaude Opus 4.7(SWE-Bench Pro 78.2%)が頭一つ上、コストはGemini 3.1 Proが半額〜1/6。「ハルシネーション抑制が最優先」「ChatGPTエコシステムを使いたい」「メモリ機能を活用したい」場合にGPT-5.5が最適、と整理するのが正確です。
Q9. 既存システム(既存のChatGPT利用フロー)からの移行は大変?
同じChatGPTサブスクの範囲内ならモデル選択メニューを5.5に変えるだけ。API利用なら`model`パラメータを変更するだけで、コード変更は最小限です。プロンプトの再調整は推奨(5.4向けに作ったプロンプトは5.5で「過剰丁寧」になる場合があります)。
Q10. 助成金や補助金で導入できますか?
IT導入補助金2026・人材開発支援助成金などが活用可能なケースがあります。具体的な要件は補助金ナビで最新情報を確認してください。研修費用が補助対象に含まれるパターンが多いので、導入時に併せて検討する価値があります。
GPT-5.5 導入前チェックリスト
本格導入前に、以下12項目を確認しておくと事故率を大きく下げられます。
- ☐ 契約プラン(Plus / Pro / Business / Enterprise / API)が業務量に合っているか
- ☐ 機密データのモデル学習オプトアウト設定が完了しているか
- ☐ メモリ機能の運用ルール(共有範囲・更新頻度・削除)が策定されているか
- ☐ ハルシネーション検知の仕組み(出典必須・人間チェックポイント)が組み込まれているか
- ☐ 業界規制・社内規程への適合確認が完了しているか(特に金融・医療・法務)
- ☐ 個人情報を扱う場合の個人情報保護法・業界ガイドラインへの準拠が確認されているか
- ☐ API利用の月額上限アラート(コストキャップ)が設定されているか
- ☐ 5.4 / 5.5 の使い分けルールが社内文書化されているか
- ☐ 業務委託先(士業・コンサル)にAI利用方針を共有しているか
- ☐ 失敗時のロールバック手順・連絡フローが整備されているか
- ☐ 全社向けAI利用ガイドラインのドラフトが存在するか
- ☐ KPI測定(精度・時間削減・事故件数)の仕組みが運用開始時から組み込まれているか
今日からできる3つのアクション
- ChatGPT Pro契約してGPT-5.5を起動 — まず手を動かして5.4との体感差を確認
- 自社で事実精度が業務クリティカルな作業3つを書き出す — 5.5の優位性が効く領域を可視化
- 1業務で2週間A/B検証 — 5.4 vs 5.5、ヒヤリハット件数・時間削減を計測
次回は「GPT-5.5 メモリ機能の実装ベストプラクティス|長期案件管理・コンサル業務での活用法」を予定しています。
著者プロフィール
佐藤傑(さとう・すぐる)
株式会社Uravation代表取締役。X(@SuguruKun_ai)フォロワー約10万人。100社以上の企業向けAI研修・導入支援。著書『AIエージェント仕事術』(SBクリエイティブ)。SoftBank IT連載7回執筆(NewsPicks最大1,125ピックス)。
関連記事
- GPT-5.4 完全ガイド|PC操作・105万トークン・料金
- Codex完全ガイド|GPT-5.3-Codexの使い方・料金・Claude比較
- Codex料金完全ガイド|2026年最新4プラン徹底比較
- Claude料金プラン完全比較|Free/Pro/Max/Team/Enterprise
参考・出典
- Introducing GPT-5.5 — OpenAI公式(参照日: 2026-04-24)
- OpenAI releases GPT-5.5, bringing company one step closer to an AI ‘super app’ — TechCrunch(参照日: 2026-04-24)
- OpenAI Releases GPT-5.5, a Fully Retrained Agentic Model — MarkTechPost(参照日: 2026-04-24)
- OpenAI’s New GPT-5.5 Powers Codex on NVIDIA Infrastructure — NVIDIA公式ブログ(参照日: 2026-04-24)
- GPT-5.5 benchmarks show a 60% hallucination drop — Startup Fortune(参照日: 2026-04-24)
- GPT-5.5 vs Claude Opus 4.7: Benchmarks & Pricing — Digital Applied(参照日: 2026-04-24)
著者: 佐藤傑(さとう・すぐる)
株式会社Uravation代表取締役。早稲田大学法学部在学中に生成AIの可能性に魅了され、X(旧Twitter)で活用法を発信(@SuguruKun_ai、フォロワー約10万人)。100社以上の企業向けAI研修・導入支援を展開。著書『AIエージェント仕事術』(SBクリエイティブ)。SoftBank IT連載7回執筆(NewsPicks最大1,125ピックス)。
ご質問・ご相談は お問い合わせフォーム からお気軽にどうぞ。
全社導入の判断材料をそろえる
- 法人の生成AI導入・社員研修ガイド — 費用・助成金・ROI
- 生成AI研修に使える助成金 — 人材開発支援助成金の実務
AI導入、要件整理から一緒にやります
100社以上・研修4,200名以上の実績。ツール選定から設計・社内展開まで、実務目線で伴走します。
- 100社以上・研修4,200名以上の実績
- 初回30分無料・即日返信
お問い合わせフォームから24時間以内にUravation担当者がご返信します。











